

This is part 3 – Graph Schema Languages – of our 4 part warts-and-all introduction to graph technologies. It covers RDF, Property Graphs, Graph Schemas, Linked Data,and concludes with an article called Why Graph Will Win. It should give you a solid introduction to the world of graph and associated challenges, while also offering a firm view that graph is the correct way to approach these complex problems. Enjoy!
The third part of this series will cover the features and attempts to support the definition of schemata — rules defining the shape of the graph. Almost all of this work has been confined to the world of RDF — labeled property graphs, by contrast, with their pragmatic focus on simplicity, took the approach of delegating the schema to code rather than imposing it in the data layer, only supporting primitive, low-level constraints on the basic node-edge structure.
Graph Schema Languages – RDFS
A somewhat bewildering series of standards and extensions have been built on top of RDF, mostly standardized by the W3C standards committee. This is where things get both really brilliant and ridiculously absurd. Shortly after publishing the RDF standard, the focus of researchers and standards bodies moved onto the problem of defining a schema to constrain and structure RDF graphs.
This led to the publication of RDFS — the RDF Schema language in 2001. RDFS provided a variety of mechanisms for defining meta-data about graphs — most significantly, a concept of a class (rdfs:Class), a subclass (rdfs:subClassOf), and a mechanism for defining the types of the nodes on each end of a triple (rdfs:domain and rdfs:range).
These were important and much-needed concepts – class hierarchies and typed properties are by far the most useful and important mechanisms for defining the structure of a graph – they are the cake, everything else is icing. They allow us to specify, for example, that an edge called “married_to” should join a person node with another person node and not, a giraffe, for example.
However, although the standard included all the most important concepts, once again, their definitions turned out to be completely wrong – their specified semantics didn’t actually allow them to be used to define typed properties, and the things that they did allow people to specify turned out to be things that nobody wanted to specify.
RDFS simply died out, but not before causing a great deal of frustration and pain among those who tried to use them, under the assumption that the standards body wouldn’t produce something that just didn’t work.
The only predicates that they defined that were ever really used as defined were the simplest ones: rdfs:label and rdfs:comment, because they were both useful and were so simple and obvious that it was not possible to screw up their definitions.
Graph Schema Languages – OWL
Then, a couple of years after RDFS was released, the W3C released another language for describing RDF graphs, but this one was entirely a different proposition — while the earlier efforts had been driven by web engineers, this time some of the world’s foremost formal logicians were the driving force – people such as Ian Horrocks and Peter Patel-Schneider.
OWL — the Web Ontology Language — was the outcome and it went far, far beyond its predecessors in terms of formal correctness and expressiveness. Not only did it include the fundamentals — class hierarchies and typed properties, but it supported set-theoretic operations — intersection, unions, disjoint classes — with a firm basis in first order logic — not enough to describe everything you might want to describe a graph, but many times more than anything else that has existed before or since.
The trouble was, however, that along with the beautiful elegant logic, the academics brought their impracticality with them and they brought it into the standards committee sausage factory – the language was effectively defined by a standardization body – the worst possible example of design by committee.
The logicians involved have compiled some reasonably scathing and amusing descriptions of the process and their personal anecdotes are often hilarious — where political arguments about removing the “OR” operator as a means of simplifying the language were debated by people who clearly did not understand what they were arguing about.
In any case, from a language design point of view, the results were horrific. For example, while recognizing that rdfs:domain and rdfs:range had been misdefined, the committee decided to retain both predicates intact in OWL but to change their definitions — in order to appease vendors who had already produced RDFS implementations. This meant that, rather than doing the sensible thing and defining new owl:subClassOf owl:domain owl:range predicates, the OWL language makes everybody include the rdfs namespace in every Owl document so that they can use rdfs:subClassOf, rdfs:domain and rdfs:range even though these predicates have completely different definitions within OWL – I’m still amazed that this one wasn’t laughed out the door.
A variety of other measures were included to appease existing vendors — various subsets of the graph schema language organized along misconceived classes of computational complexity which went on to confuse students eternally because they made no sense in terms of mathematical computational complexity. None of this was made at all clear, of course, it was presented as a sensible and logical structure, and still, to this day, almost nobody realizes just how ridiculous these decisions were – these are complex documents handed down by the gods and any incomprehension is due to the reader not getting it.
Even though the language had a nice terse representation – the Manchester syntax – this was immediately sidelined in favor of an arcane, awkward, and verbose RDF representation.
However, while the design by standards committee sausage factory produced a language design that was about as terrible as anybody could have managed if they were trying, these were mainly just syntactic issues that could be overlooked.
What really killed OWL was the impracticality and idealism of the academics. They wanted a language that was capable of usefully describing an ‘open world’ — situations where any particular reasoning agent did not have a complete view of the facts — the idea being that such a regime was necessary for talking about the great new inter-linked world wide web, where information might be scattered to the four corners, and just because any individual agent did not know about a fact, it could not be assumed that it was not out there somewhere in the vast expanse of the digital world wide web.
Open world reasoning such as this is a very interesting and commendable, and sometimes highly useful, field. However, if I have an RDF graph of my own and I want to control and reason about its contents and structure in isolation from whatever else is out there, this is a decidedly closed world problem. It turns out that it is essentially impossible to do this through open world reasoning. If my database refers to a record that does not exist in my database (i.e a breach of referential integrity) then it does not matter whatever else exists in the world, that reference is wrong and I want to know about it. I most especially do not want my reasoning engine to decide that this record could exist somewhere else in the world — if it is not in my database it does not exist and I know this. If I cannot manage my own database and make sure that it is not full of errors, then it does not matter what else exists in the world because my house is built on a pile of mud. I can’t even control what’s in my own bloody database that I control entirely, who am I kidding that I can start reasoning about the universe beyond.
What’s worse, there is absolutely no good reason not to include support for a closed world interpretation in OWL — you don’t even have to change a single piece of the language. You can just introduce a much simpler, more intuitive, and much easier to implement interpretation. And closed world reasoning does not preclude open world reasoning – they are easy to use together because all databases that conform to an OWL ontology through a closed world interpretation are, by definition guaranteed to also conform to that same ontology under an open world interpretation.
Graph Schema Langagues – SHACL
Eventually, this glaring omission was addressed but it took more than a decade for the SHACL standard to emerge — a constraint language for RDF graphs. Unfortunately, by then the logicians had abandoned ship while the sausage factory remained — the standard that came out was once again full of logical inconsistencies and impractical and wrong design decisions.
Meanwhile, the semantic web community powered along in academia regardless, building castles in the sky — full of projects that aimed to build global federated semantic infrastructure which inevitably failed completely due to the fact that the bricks were made of paper.
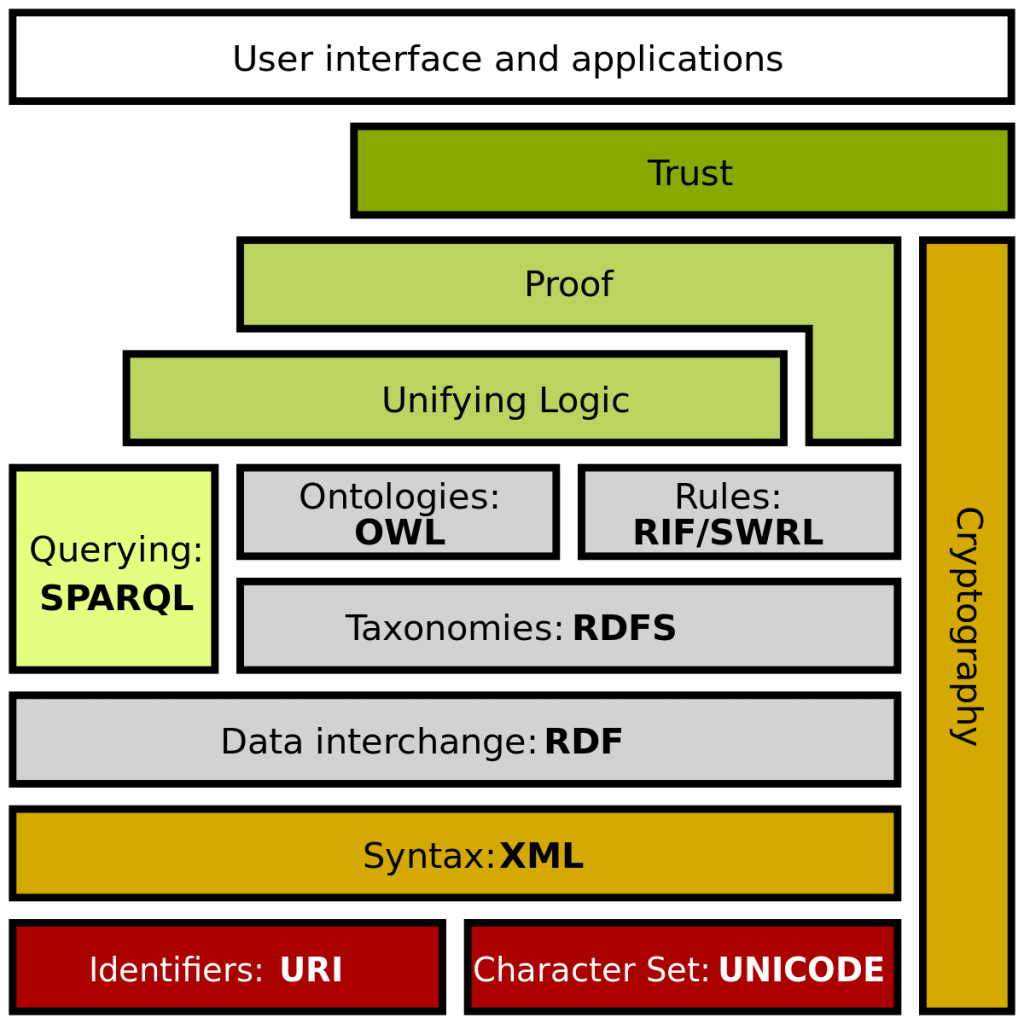
And this is only the tip of the iceberg — there have been many more incoherent standards and initiatives that have come out of the W3C’s standards bodies — almost all of which have launched like lead balloons into a world that cares not a jot.
Nevertheless, it is important to recognize that, hidden in all the nonsense, there are some exceptionally good ideas — triples, URL identifiers, and OWL itself are all tremendously good ideas in essence and nothing else out there comes close.
It is a sad testament to the suffocating nature of design by standards committee which has consumed countless hours of many thousands of smart and genuine researchers, that ultimately the entire community ended up getting its ass kicked by a bunch of Swedish hackers with a bunch of JSON blobs — the Neo4j property graph guys have had a greater impact upon the real world than the whole academic edifice of semantic web research.
Here’s an article to help, that discusses patterns and principles for graph schema design in TerminusDB.
The final part of the warts-and-all Graph Fundamentals series focuses on Linked Data.