I recently published a warts-and-all 4 part introduction covering RDF, Property Graphs, Graph Schemas, and Linked Data. You would be forgiven for concluding that I am not a fan of Graph databases or RDF. One reader on Twitter even accused me of “shitting on RDF”(!).
It’s important to be frank about the problems of graphs and RDF and not just whistle the marketing tune because as soon as the technology is out there in the hands of developers, they will find the problems and will be inclined to reject the technology as pure hype if all they have heard are songs of breathless wonder.
In the last couple of years, while trying to sell graph databases into bricks and mortar companies, by far the most hostile reactions I’ve come across have been from technologists who got bitten by the Semantic Web bug in the early 2000s. Once bitten twice shy.
However, if you were to assume that I’m a critic of graph databases, you would be very wrong. I’ve spent most of the last decade building graph database management systems because to me, it’s incredibly obvious that in the long run, graph databases are going to win, and here’s why.
Graph Databases Are Closer to the Way Humans Perceive the World
The point of all databases is to provide as accurate a representation of some aspect of external reality as possible.
The fundamental advantage of graph databases is that they model the world as things that have properties and relationships with other things.
This is closer to the way that humans perceive the world – mapping between whatever aspect of external reality you are interested in and the data model is an order of magnitude easier than with relational databases.
Everything is pre-joined in graph databases, you don’t have to disassemble objects into normalized tables and reassemble them with joins.
And because creating and curating large and complex datasets is very difficult, very expensive, and potentially very lucrative, the reduction in technical complexity in creating and interpreting the graph data model is irresistible.
The knowledge graphs that companies like Google and Facebook have accumulated are demonstrably commercially powerful and it is unlikely that such complex and rich datasets would have been possible without graph.
Humans have an evolutionarily pragmatic view of the world. We perceive the world as things that move through space and time. These things have properties that may change over time. They also have relationships with other things which may also change over time.
The model is simple but there are a great many different types of things – from stones, to mirrors to politicians and honeybees. To make sense of these things and their properties, we organize them into types and organize these types into a ‘tree-of-life’ or more broadly a ‘tree-of-things’ – taxonomies of types of things that share certain properties and relationships with other types of things.
Whether you are building a database to record the known universe or logging network security incidents, the model that you actually want to record is always a bunch of objects, categorized with a type-taxonomy, with properties and relationships with other objects, some of which change over time.
That’s what you always want to record, because that’s how you perceive the world. Any indirection between the perceived world and the recorded model creates extra complexity at every step of processing. And in the world of complex systems, combinatorial explosion of complexity is the one true enemy.
Reducing the complexity in each and every data operation is irresistible in the long run – you can focus on other things rather than the mappings between the aspects of the real world that you want to model and their stored representations.
In this respect, even the simplest graph database such as Neo4j – which models the world as a bunch of JSON documents, some of which may contain pointers to other JSON documents, is much better than even the fanciest RDBMS. Granted there is no taxonomy or schema, and support for temporality is basic, but it’s easy to produce a much more naturalistic model of the world than will ever be possible if you have to break the things up into relations.
Of course, it is possible to automate this mapping by delegating the problem to code (for example by using ORMs or system meta-models) but this is a short-term fix that blows up as size and complexity increase.
Code has unbounded complexity and is largely opaque to automated analysis – its contribution to combinatorial explosion becomes overwhelming at scale. All systems which are built upon ORMs evolve into ORM maintenance systems.
Database Modeling Power
The diagram below shows how different database technologies rank in terms of their data-modeling power – the extent to which they allow you to create naturalistic models of the world. To briefly explain the categories:
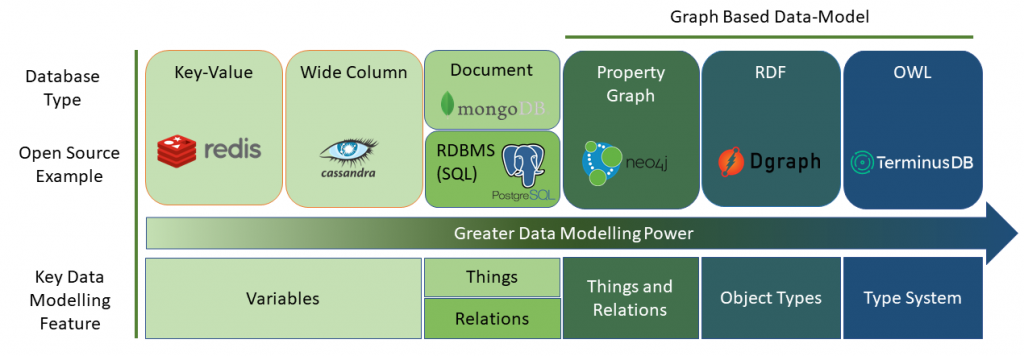
Key Value Stores and Wide Column Stores
These databases exist primarily to provide computer programs with somewhere to save the variables that they use. They lack data-modeling features beyond basic datatypes. There is nothing wrong with this — computer programs need databases too.
It is also, of course, possible to assemble complex data models from these atomic units within programs, but this very quickly runs into the combinatorial explosion problem – almost everything is described in code leading to unbridled complexity growth.
Document Stores
Document stores typically store data as a set of JSON documents: objects with tree-structures.
The big feature of these databases over relational is that these documents are suitable for creating naturalistic models of things, with the tree structure expressing a containment (or has-a) relationship type.
However, they are severely crippled because of poor support for modeling relationships – document relations are often expressed through embedding duplicates of other documents — a horrible, awful, solution that massively increases complexity over time.
Relational Databases
Relational databases are all about relations: tables that can be joined together to form new relations.
Foreign keys are used to express schematic relationships between tables. These relationships are untyped and semantically meaningless integers or strings are commonly used as keys.
As a result relational databases are fairly impoverished in terms of their ability to capture real-world relationships – we can’t distinguish between containment (has-a) and other types of relationships so we can’t actually turn these relations back into objects without information that is external to the system – mostly in glue code or ORMs.
Furthermore, translating to and from these relations and real-world objects is rather intricate and leads to a very complex data model even for relatively simple aspects of the real world.
Property Graphs
Property graphs are basically document stores with a dash of relations added in, that is to say, they are just a bunch of JSONs with some properties acting as special links to other JSONs (the in and out properties of edges).
Even though they are quite primitive, they still have the most important features needed to create naturalistic models of the real world — things (nodes) with properties and relationships (edges).
RDF Graphs
RDF graphs have all of the features of the database models to the left in the above diagram, the thing that they really bring to the party is the concept of object types – via the rdf:type predicate – and not just simple datatypes.
OWL Graphs
Graph databases that use the Web Ontology Language (OWL) to describe their data model are by far the most powerful in terms of data modeling capabilities, although OWL must be used with care as it can easily lead to an incomprehensibly complex data model (and in practice, we need to choose a computable fragment of the language).
Nevertheless, the really important aspects can be boiled down to 3 simple predicates that enable relationships between object types to be defined – rdfs:domain and rdfs:range support strongly typed relationships between objects, not just simple relationships, while rdfs:subClassOf supports type inheritance – and hence proper taxonomies – these combine to provide a fully-featured type system, the holy grail of data modeling.
So, while some people may feel that recent interest in graph databases is just another fad, I’m putting my money on graph – 20 years from now, non-graph databases will be for niche and legacy applications.
If you want a more detailed read about Graph Databases, I published the following articles as part of the Graph Fundamentals Series:
- Part 1: RDF DB
- Part 2: Labeled Property Graphs
- Part 3: Graph Schema Languages
- Part 4: Linked Data