An Open Source Graph Database & Document Store
TerminusDB is an in-memory, distributed and open-source graph database and document store. At its heart is a collaboration model providing Git-for-data features such as branch, merge, workflows, and revision control.
CI/CD for your Database
TerminusDB is a powerful open-source graph database. It is immutable and can query any past or present commit. Versions of everything are stored in an extremely compact delta format providing fast query access. This enables highly performant CI/CD data management for stable development environments, frequent iterations, and predictable deployments.
# Create database
terminusdb db create admin/philosophers
# Add a schema
echo '{ "@type" : "Class",
"@id" : "Philosopher",
"name" : "xsd:string" }' | terminusdb doc insert admin/philosophers -g schema
# Add a JSON document
echo '{ "name": "Socrates" }' | terminusdb doc insert admin/philosophers
# Get the document back
terminusdb doc get admin/philosophers
# Prove that it works, Socrates is there!
# Branch the database
terminusdb branch create admin/philosophers/local/branch/changes --origin admin/philosophers
# Add more philosophers to new branch
echo '{ "name": "Plato" }' | terminusdb doc insert admin/philosophers/local/branch/changes
echo '{ "name": "Aristotle" }' | terminusdb doc insert admin/philosophers/local/branch/changes
# Look at the difference between branches
terminusdb diff admin/philosophers --before-commit main --after-commit changes | jq
# Apply the differences to main
terminusdb apply admin/philosophers --before-commit main --after-commit changes
# Look at the difference again
terminusdb diff admin/philosophers --before-commit main --after-commit changes | jq
#!/usr/bin/env python3
from terminusdb_client import Client
from random import random
client = Client("http://localhost:6363", account="admin", team="admin", key="root")
client.connect()
db_name = "philosophers" + str(random())
client.create_database(db_name)
client.connect(db=db_name)
# Add a philosopher schema
schema = {"@type": "Class",
"@id": "Philosopher",
"name": "xsd:string"
}
# Add schema and Socrates
client.insert_document(schema, graph_type="schema")
client.insert_document({"name": "Socrates"})
# Verify that it added in the DB
print(list(client.get_all_documents()))
# Create new branch and switch to it
client.create_branch("changes")
client.branch = "changes"
# Add more philosophers
client.insert_document({"name": "Plato"})
client.insert_document({"name": "Aristotle"})
# Diff the branches
diff = client.diff_version("main", "changes")
print(diff)
# Apply the differences to main with apply
applied = client.apply("main", "changes", branch='main')
print("Applied:")
print(applied)
# Diff again
diff_again = client.diff_version("main", "changes")
print("Second diff:")
print(diff_again)
const Client = require('@terminusdb/terminusdb-client');
const client = new Client.WOQLClient(
'http://127.0.0.1:6363',
{
user: 'admin',
key: 'root',
},
);
async function main() {
// Create a database
await client.createDatabase('philosophers', {
label: 'Philosophers',
comment: 'Philosophers by name',
schema: true,
});
// Add the philosopher type
const schema = {
'@type': 'Class',
'@id': 'Philosopher',
name: 'xsd:string',
};
await client.addDocument(schema, { graph_type: 'schema' });
// Add Socrates
await client.addDocument({ name: 'Socrates' });
// Get back all documents
const doc = await client.getDocument({ as_list: true });
console.log(doc);
// Create a branch
await client.branch('changes');
// Add more philosophers to the new branch
await client.addDocument({ name: 'Plato' });
await client.addDocument({ name: 'Aristotle' });
// Look at the differences between branches
const diffs = await client.getVersionDiff('main', 'changes');
console.log(diffs);
// Apply the differences to main
client.checkout('main');
await client.apply('main', 'changes', 'apply changes');
// Check the for any remaining differences between branches
const remaining_diffs = await client.getVersionDiff('main', 'changes');
console.log(remaining_diffs);
}
main();
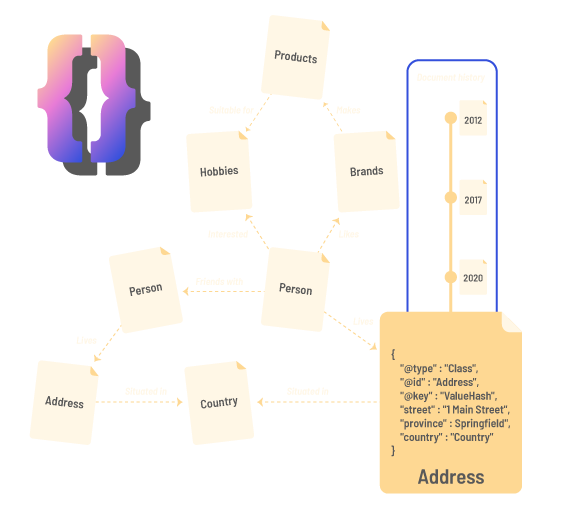
A document-oriented graph database with version control & collaboration model
TerminusDB is designed to make knowledge graph management easier. It combines JSON’s ease of use with the power of graph query. The collaboration model lets many data curators (human and machine) work concurrently with safety and review.
Store Small, Scale Big
TerminusDB has the lowest memory overhead around. Succinct data structures and delta encoding keep things small, just 13.57 bytes per triple. Scale to any size your memory availability allows.
Schema First
The flexible and extendable type-checked schema based on a JSON syntax acts as a blueprint to model data and develop scalable applications.
Auto UI Generation
Document frames for creating, editing and viewing data are automatically generated from your schema. UI SDK tools make building front ends quick and easy.
Git for Data
A versioning first database, fork, clone, branch, and merge, just like Git, to collaborate with colleagues, time travel, and develop with the safety of undo.
Document Oriented
Work with JSON documents and build relationships between documents in a powerful knowledge graph.
Complex Data Management
Take a Technical Deep Dive
TerminusDB CTO and Co-Founder, Gavin Mendel-Gleason, has written a three-part blog explaining the technical internals of the open-source graph database and document store, TerminusDB. If you want a technical overview without marketing talk, this series is ideal for you.

TerminusDB Internals
Part 1 of TerminusDB Internals, looks at the guts and how we’ve built an in-memory graph database to avoid thrashing and slow performance.

TerminusDB Internals Part 2
Part 2 of TerminusDB Internals looks at how we deal with mutating data with succinct data structures and graph storage.

TerminusDB Internals Part 3
Part 3 of TerminusDB Internals looks at how we sort data lexically and how we have overcome some of the issues that come with this approach.

Read to Get Started?
Start building today with TerminusDB. Follow the link below to the installation documentation.