At TerminusDB towers, we are on a journey to bring knowledge graph management to the masses. It’s been our focus for a couple of years now. This article explains how we are doing this.
Graph vs Relational
The Internet age makes us all compete. Which is best, graph or relational? Messi or Ronaldo? The EU or the USA? Who is the GOAT?
In reality, a more measured approach does not always need to compare everything. Instead, let us appreciate things for what they are.
Relational databases will continue to be the dominant force in the data world because they solve the most common use cases. They are ideal for tasks that involve organizing structured data with well-defined relationships between tables, making them particularly suitable for applications like e-commerce transactions and product catalogs.
Graph databases are ideal for tasks that involve representing and querying complex relationships and connections between data entities, making them particularly suitable for social networks, recommendation systems, fraud detection, and knowledge graphs.
They are different tools for different tasks and can quite happily coexist.
The Problem with Graph Databases
Neo4j is probably seen as the most successful graph database available in the market today, its website states that it has been downloaded 36 million times. Yet despite the popularity, graph databases have not delivered against massive growth forecasts predicted by the likes of Gartner. The reasons for this underperformance are twofold –
- High technical barrier – As mentioned, relational databases and SQL are the dominant force in data management and someone moving from relational to graph faces a steep learning curve. So much so that it is a major obstacle to adoption. MongoDB’s document approach is the perfect example of how easy onboarding is a great way to gain user traction (the fifth most popular database according to DB-Engines) even though Mongo users face big problems when scaling or if they need a schema or require joins and relationships.
- The need for collaboration – Particularly in the field of knowledge management, knowledge graphs need collaboration management to oversee human and machine data curators. Without adequate approvals and conflict-resolution tools, data quality suffers and projects fail.
These two problems are what TerminusDB and TerminusCMS solve. Let’s look at how.
The Document Graph
TerminusDB’s underlying storage structure is an RDF triple store.
Unlike other graph databases, TerminusDB takes a different approach to how it handles data. Data products have a specific context for which they are authoritative, essential for enterprise data management where the accuracy of data is paramount. The data product consists of a schema and data instances of that schema. The schema enables a document-oriented approach, enabling easy interaction from a computational perspective. Data structures in most languages are easier to match with a document approach and is how JSON as a data format has become a de-facto standard for API integration.
The JSON document approach makes it easier and more accessible for developers to get data in and out of a knowledge graph.
We have also made great strides in removing some of the OWL and RDF frustrations (you can read about the frustrations in the Graph Database Fundamentals blog) that have hampered the adoption of graph database technology. TerminusDB’s schema language uses a Literate Type Theory for JSON that specifies typed references, giving us the power of graphs with the simplicity of JSON.
Making knowledge graphs more accessible to people who want the power of graphs, but are not experts in graph technologies is essential to a wider adoption.
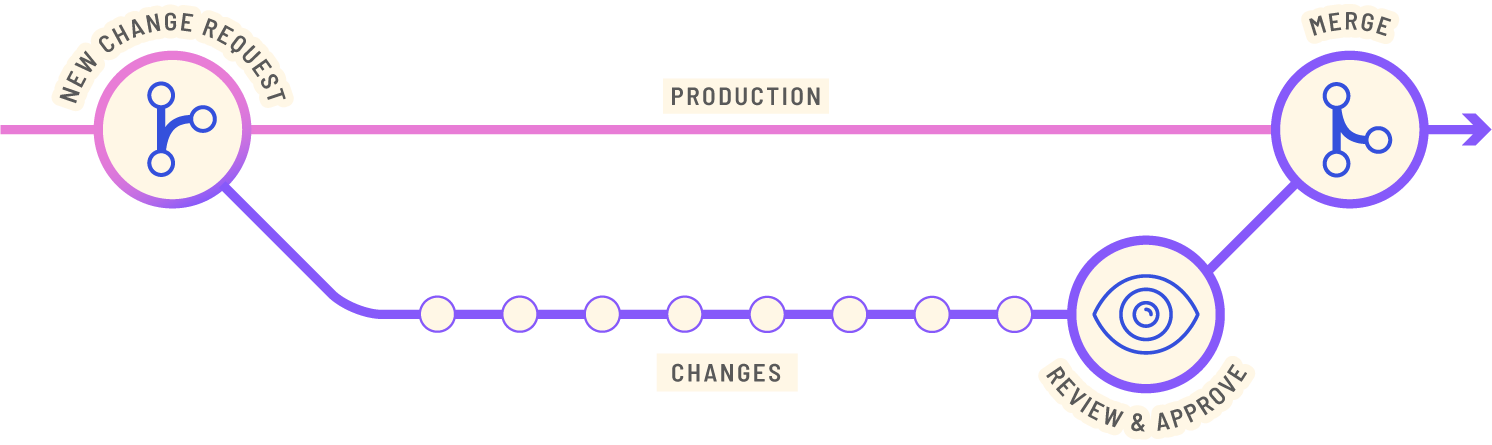
The Collaboration Model
Knowledge graphs tend to involve many data curators, human or machine. In order for many curators to work concurrently without collisions and errors is to introduce collaboration management. If anyone has tried to build this, you will know that it is hard.
TerminusDB is a product that was developed to solve a complex collaborative use case. Since its inception, we have matured into an attractive product, but at its core is still the collaboration model that inspired its creation.
TerminusDB is immutable and keeps versions of everything in an extremely compact delta format (succinct data structures). Because all versions are stored, TerminusDB can query any past or present commit. Each data product in TerminusDB is actually a collection of graphs that track not only your data but important information about your data.
For example, repository graphs enable collaboration. They help us understand how to communicate with other TerminusDB instances. Commit graphs provide revision control. They contain information we need to travel in time, branch, squash, reset, rebase, and merge. The other graphs include branches and layers and you can read about them in this write-up from a fellow Terminator.
The collection of graphs enables the collaboration model to function and make TerminusDB unique in the knowledge graph management space. It is a feature that most of our users need and how they find us.
Curating knowledge graphs requires collaboration management and TerminusDB’s collaboration model provides –
- Version control
- Pull requests/change requests
- Diff and patch
- Data provenance.
- Time travel
- Branch, clone, merge, rebase, rest, and squash
All at the database layer.
Will Someone Think of the Front End Developers!
Being able to extract value from data is the reason why billions are spent on data management each year. Whether it’s for decision-making or in applications, data needs to be accessible to the people who need it. The difficulty of graph databases has hindered this access, but again the TerminusDB team has worked hard to make this process easier and faster.
JSON helps and so does TerminusDB’s schema language. The latter, and patented technology takes your data model and automatically generates document editing frames in the form of our document explorer. The document explorer is a ready-made UI for curating knowledge graph data. Once the schema is modeled, you have a ready-to-go UI.
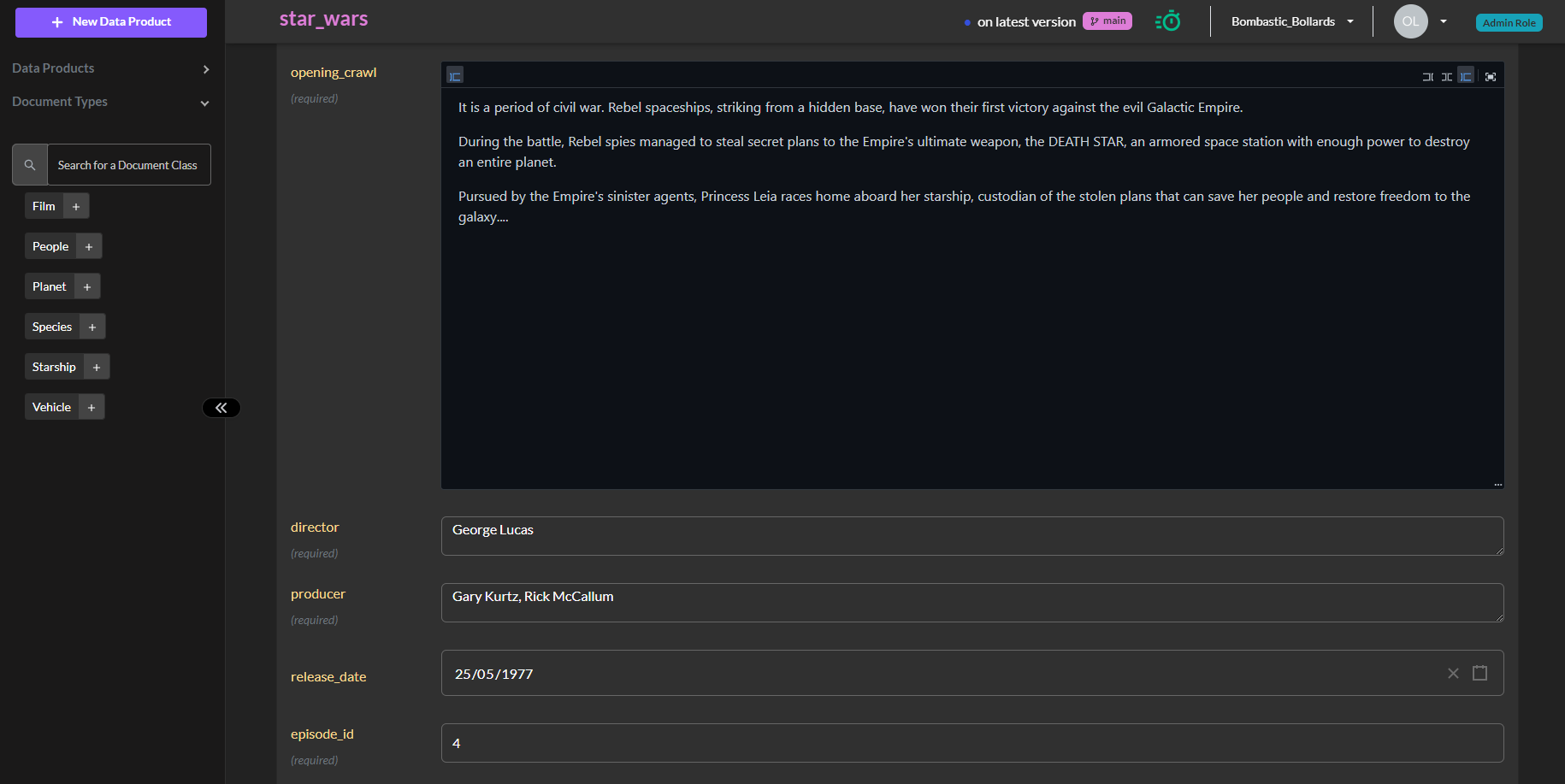
Furthermore, TerminusDB includes document UI templates so you can take the document explorer functionality and style it to use as your own. There is also a UI SDK to build applications directly from schema-generated document frames using popular frameworks such as React.
Better Knowledge Graph Management
There are plenty more features in TerminusDB and TerminusCMS such as vector search, but for the sake of focus, we’ll not expand on these here.
Knowledge graphs have an important role to play in both society and enterprise data management. They will solve the biggest problems by connecting data and its relationships. The products on the market have made great strides in academic circles but have failed to deliver for enterprise users due to their complexity and the issue of collaboration management.
TerminusDB’s document-oriented graph approach coupled with its collaboration model brings knowledge graph management to the masses by lowering technical barriers and facilitating collaborative curation of quality data.
New to Graph Databases?
Our warts-and-all overview of graph databases covers everything from RDF, property graphs, linked data and graph schema languages and is a good place to start for those looking to learn more.