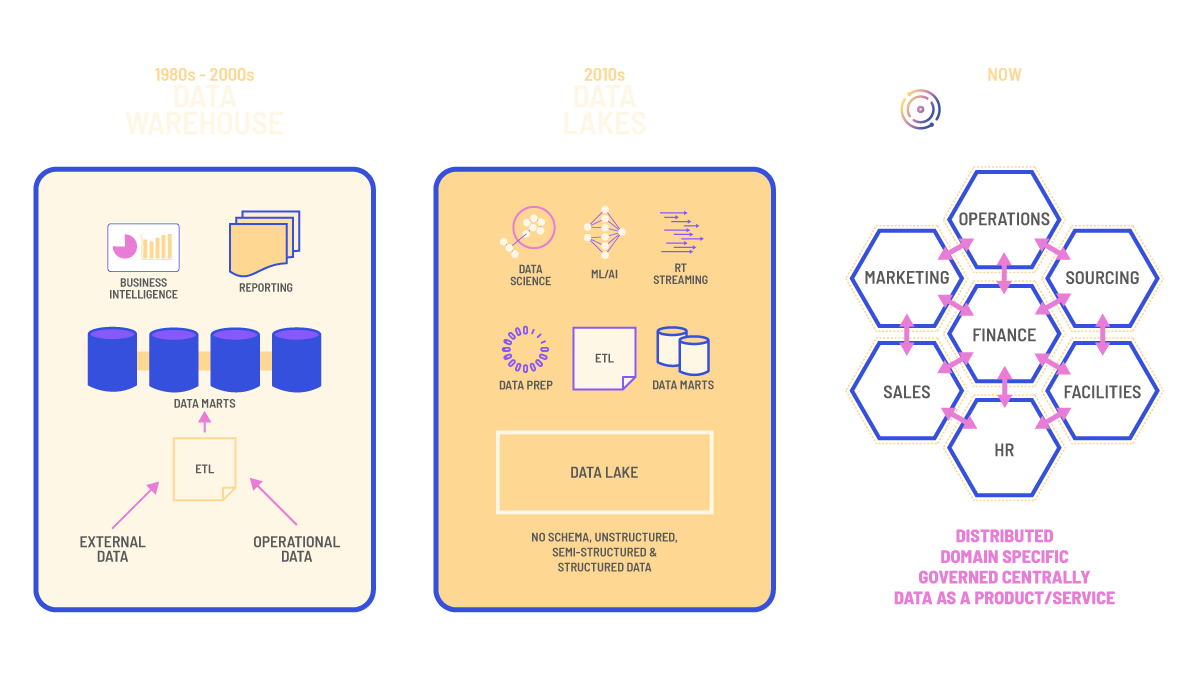
You may have heard the term data product being talked about in recent months. We thought we’d take time out to explain what is a data product and how treating data like a product can help organizations improve data accuracy, accessibility, and security.
Data products were traditionally thought of as data products that consumers buy, think streaming services such as Netflix selling digital content. That, of course, is quite correctly a data product. In this instance, however, it is the wrong context. It is not what we and our peers mean when we talk about what a data product is.
In short, data products are the principle of treating data as a product. That means getting data to an adequate condition for data customers to consume. When we say data customers, we mean anybody related to an organization who needs the data for a particular function. For example, a financial controller needing sales data, a marketing person needing product data, or a customer wanting to see their account details. Alternatively, it could be data analysts needing specific information for predictive modeling, or software developers requiring data for application development.
Domain team ownership
Treating data as a product requires domain ownership. A domain is essentially a team. The easiest way to think of them is departmental, but it may vary depending on the type of organization. Domains have responsibility for their own data product(s). The domain is the subject matter expert for all the data generated within their realm. They understand what the data means and the context of it. Using the Netflix example, a domain might have responsibility for subscriptions, while another domain may handle show and movie recommendations. Each domain will have its own data and will understand the data context.
As well as the data that a domain generates, a data product should also enable other domains to use their data. Data mesh pioneer Zhamak Dehghani talks about calling for a new principle, self-serve data infrastructure as a platform to enable domain autonomy. A data product is about its data customers and data must be made available to those who need it, but equally important is to provide those customers with the ability to help themselves to what they need when they need it. Self-serve data.
The principles of treating data as a product
In order for data to be treated as a product it must be principled to ensure that data customers are happy customers, below is a list of Zhamak’s principles that are sound and logical, a data product must be:
- Discoverable: We’re back to square one if data isn’t discoverable. Ideally, data as a product would have a registry, data catalog, and metadata to show lineage, owners, and source of origin.
- Addressable: A data product should have a unique address following a global convention to ensure users can programmatically access it. Ease of use is a data product objective so it’s important for common conventions to be developed.
- Trustworthy and truthful: Data is king, data is the new oil, we know the terms. If data isn’t trustworthy and truthful then it’s no use. Data product owners must take ownership of data quality and adhere to an approved service level objective. This also includes ensuring metadata is included to provide data customers with data provenance and lineage. If you intend on treating data as a product, you might want to think about Data Contracts, more information about these contracts can be found in this excellent blog by Chad Sanderson.
- Self-describing with semantics and syntax: As discussed, an integral part of a data product is to ensure that data customers can serve themselves with their data requirements with no hand-holding. Data schemas with well described semantics and syntax will help achieve self-serve data products.
- Interoperable and governed by global standards: Global standards will ensure harmonization of polyglot domain data and establish the interoperability of an organization’s data.
- Secure and governed by global access control: It may seem obvious, but secure data products are a must. Access can be managed centrally, but domain data products can then assign access at a granular level to fine tune the needs of teams.
We feel this list requires one further principle:
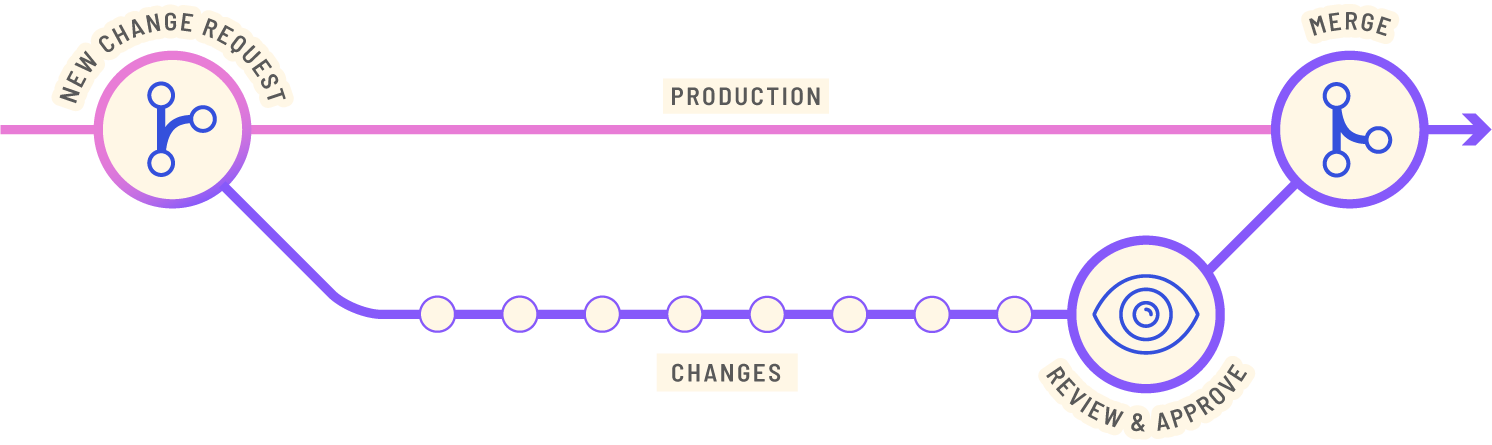
- Version control: Data requirements change, be it new sources, processes, or applications. Working with live data with no checks is dangerous and can cause costly problems for any organization. A data product should take software best practices of distributed version control so data products can be branched and tested before rolling out changes. This will enable quicker development time and less headaches for the business.
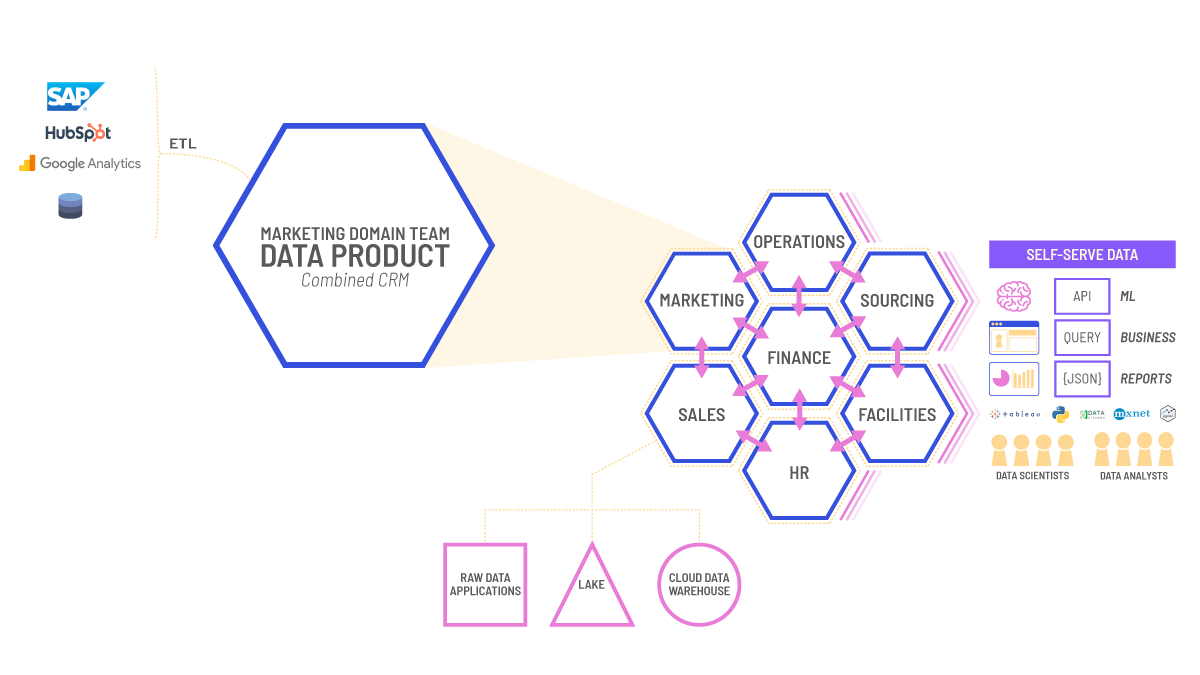
Data as a product architecture
We’re going to summarize Zhamak once again as she has already detailed the architectural requirements of a data product and we agree wholeheartedly with them. A data product should include:
Architectural quantum: The ability to deploy a data product that is independently functional and cohesive. Careful thought needs to be had regarding data models, if you want data as a product, logic dictates that you should only use data within that domain and not rely on other data products. By incorporating data from other data products, somewhere down the line, there will be changes that will break things – similar to traditional architectures that are difficult and costly to manage.
Code: All the code to include data pipelines for consuming, transforming and serving upstream downstream and code for receiving upstream data. Code for APIs providing access to data and semantic schemas as well as code for enforcing access control, compliance, and policies.
Data and metadata: The underlying analytical and historical data of that domain. The associated metadata is an important facet to provide context and governance and should include documentation, semantic and syntax declaration, and quality metrics.
Infrastructure: Enabling building, deploying, and running the data product’s code, and storing and giving access to data and metadata.
Data mesh & data products
Data products ultimately fit within a bigger picture: data mesh. Data mesh is not a technology or platform, it is a paradigm and possibly the answer to helping organizations untap their data potentials to realize the benefits of better AI, ML, knowledge sharing, applications, and services. If you haven’t already done so, we implore you to read Zhamak’s seminal blog, Data Mesh Principles and Logical Architecture. We’re not going to summarise this article, but wanted to reiterate that the principle of treating data as a product is integral to data mesh success. Treating data users as customers, where your goal is to satisfy them with truthful and discoverable data, will revolutionize the speed and agility of your organization to enable you to do countless things better. The sky is the limit!
Why do we talk about data as a product?
TerminusDB and TerminusCMS are data management platforms that treat data as a product.
Use them to build context-bounded data products with a document-oriented graph data structure. REST and GraphQL API enable self-service data and the Admin UI allows technical and non-technical people to curate and query data.
Data governance, essential for treating data as a product, is provided by the collaboration model. Terminus is immutable and keeps versions of everything in an extremely compact delta format (succinct data structures). Because all versions are stored, TerminusDB can query any past or present commit. This enables Git-like functionality for push/pull, diff, time-travel, branch and merge.
The advantage of the data product approach and the git-like collaboration and versioning abilities enables data governance over data products with clear ownership, authority and processes for updates.
Additionally, data can live in multiple places through an integrative data product-orientated approach that is ideal for data mesh scenarios.



How can data as a product improve data accuracy, accessibility, and security?
Data products are about moving away from a central warehouse or lake and about shifting responsibility away from centralized teams to a decentralized network of domains. Here’s why data products can improve data accuracy, accessibility, and security.
Data accuracy: By keeping the data with the domain responsible for it, you are ensuring that there is contextual knowledge around all of the information collected. Data teams have a much smaller pool of data to work with and a better understanding of it when cleaning and preparing it for consumption. Perhaps though, what is most crucial to data accuracy is the fact that the domain really cares about their data. If you take Maslow’s Hierarchy of Needs, you will see the tip of the pyramid is self-actualization and this is where your best employees want to be. Being creative, solving problems, and accepting facts. They want the data they are in charge of to innovate their domain, serve customers better, both internal and external, and they want to achieve great things in their job to progress and succeed. This is the fundamental reason why data accuracy will improve dramatically by empowering your domains.
Data accessibility: Treating data as a product is a principle of putting data accessibility and discovery first. Domains are responsible for preparing their data for consumption. As covered, a data product must provide self-serve functions to provide the owning domain, and other business domains, with access to the data for their own purposes. Metadata and schema semantics will provide all who need it with data context to speed up data discovery and access.
Data security: Global governance of data products is essential. Not only will governance ensure appropriate access control, but it will also enable the interoperability of organizational domains. A global policy sets the standards across all data products, but because of the granularity of data products, access to specific data products can be fine-tuned for those who really need them. Factor in the patch-up jobs of large-scale data warehouses and lakes where there is a mishmash of fixes that can be unregulated and flawed in security, then you have one less security worry. TerminusDB adds further layers of security with an immutable commit log to show all changes in data and access histories to provide tamper evidence in the event of unlawful access.
Conclusion
A data product is the responsibility of the domain and is part of a wider data mesh paradigm, to make decentralization an integral part of any organization. By moving ownership of data to the domain responsible for generating it, the organization will benefit from greater accuracy and accessibility of data. This data will make businesses more agile and, by utilizing more of the data generated, will provide better insights for future growth.
TerminusDB and TerminusCMS are data product builders that enable you to build one data product at a time. Connect data sources; create branches of data sets to test, develop, and serve; and build a vibrant ecosystem of data products, connected through a document orientated knowledge graph.