

Last week I went to a meetup where a team of software developers from Dublin talked about their newest invention — TerminusDB, a graph database that stores data like git – A git for data graph!
My reaction was like, what? Imagine all the cool things you can do with a Git for data database: time travel, branching, and forking etc.
What’s more, TerminusDB is a graph database, meaning all data is stored in nodes and edges, making it easy to extract relations between your data without all the hideous joins in relational SQL databases.
From the event, I wanted to write an article that talks about:
- What is a graph
- How Git works
- How TerminusDB Git for data Graph functionality works
What is a graph?
In mathematics, a graph is a structure amounting to a set of objects in which some pairs of the objects are in some sense “related”. The objects correspond to mathematical abstractions called nodes and each of the related pairs of vertices is called an edge [1].
The most common types of graphs are directed graphs and undirected graphs. The difference is that the edges of a directed graph have a direction from a node to another but the edges of an undirected graph do not — it just links two nodes together.
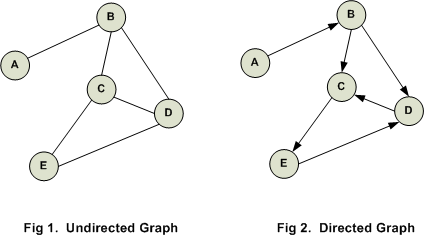
A lot of our git data can be stored in a graph, and the uses of graph databases are more than you might think, for example knowledge graphs are used by Google and NASA, and are used by recommendation engines, financial services fraud detection, and machine learning and AI.
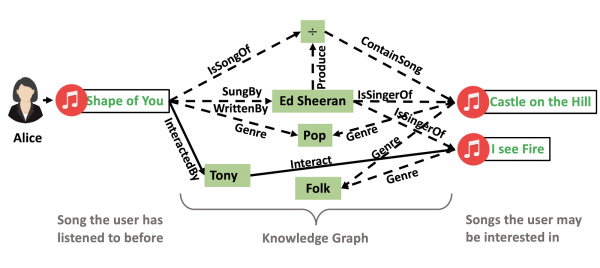
How Git works
For those who are not familiar with Git, let’s quickly recap how Git works.
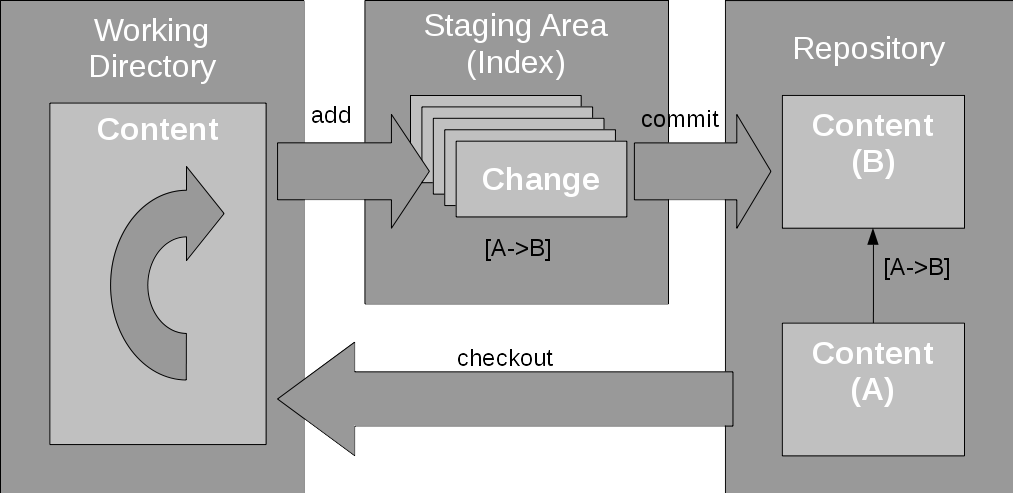
When you make changes to a Git repo, you have to add your changes to the staging area, where you then commit it. Git will store the new content and keep the different commits as a series of events.
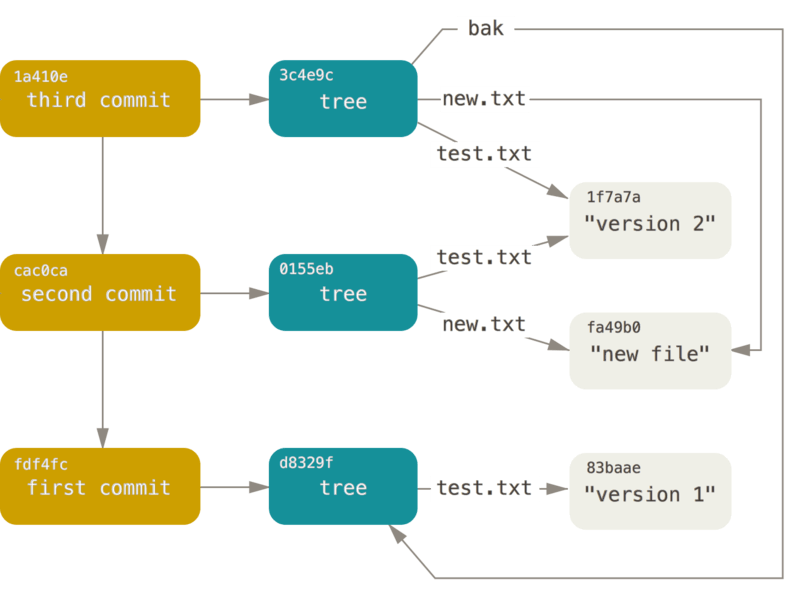
Fun fact here, counter-intuitively, Git does not store diff. Instead, it makes files into blobs and stores the repo as a tree of pointers pointing to these blobs. It also stores the commits in sequences retaining the history of the repo.
How TerminusDB works like a Git for data Database / Git Data Graph?
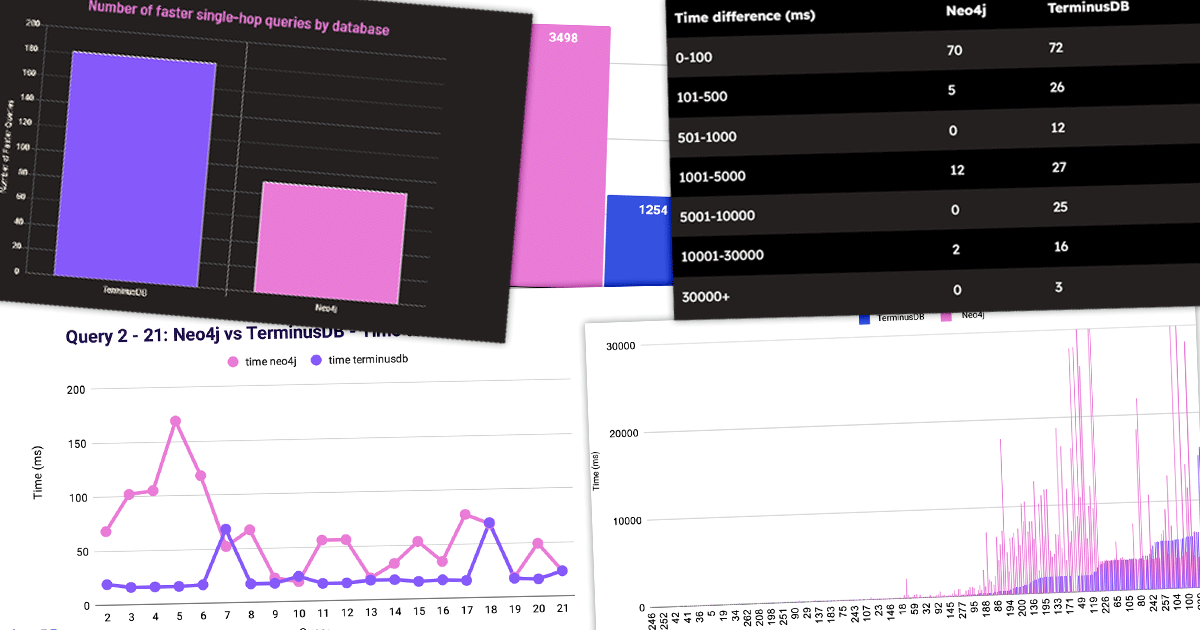
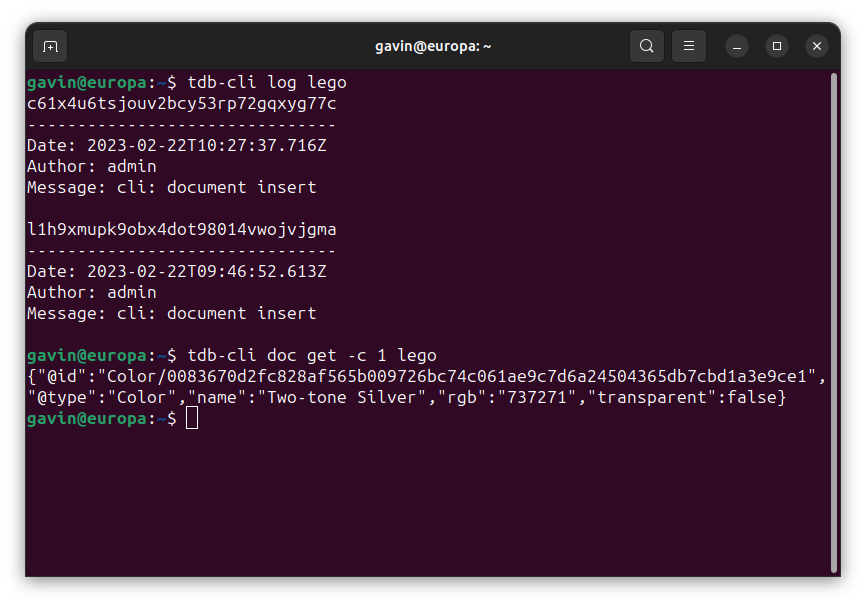
The example below shows how similar TerminusDB is to Git by storing data in a chain of commits. However, it stores the diff instead of the entire database (which is advantageous due to not having to save a huge amount of data).
For each layer, data consists of triples with edges, and the nodes that link it, stored either on the +ve plane or -ve plane (except the initial layer where everything was created). +ve means new data is added and -ve means that data is deleted.
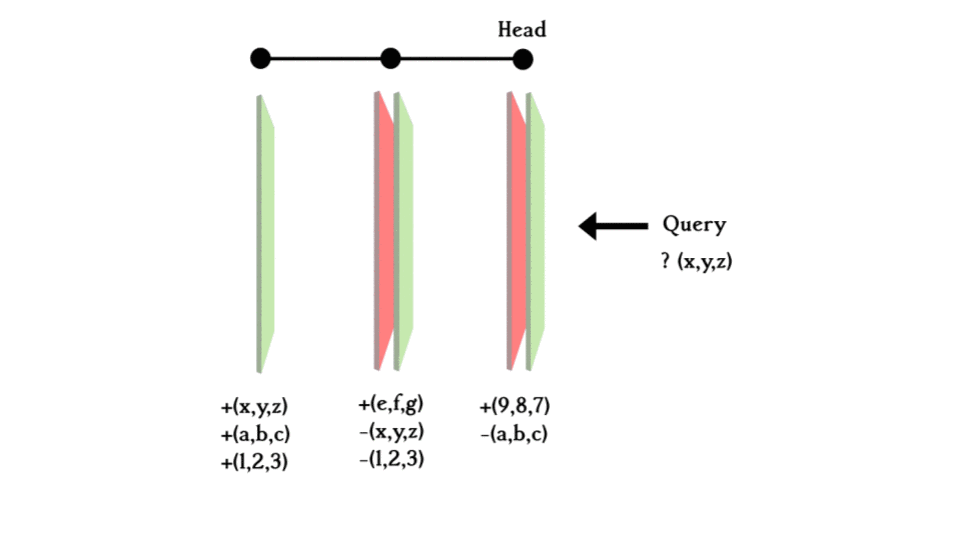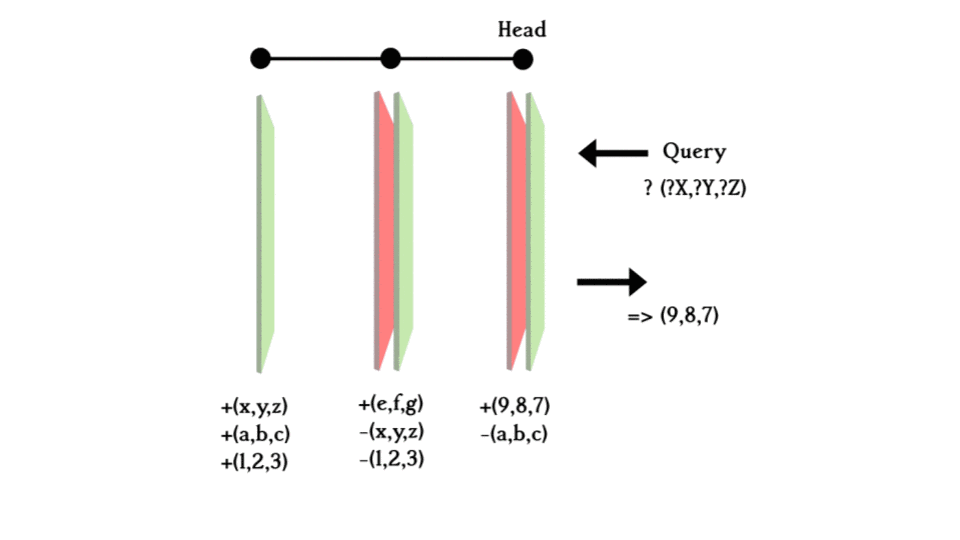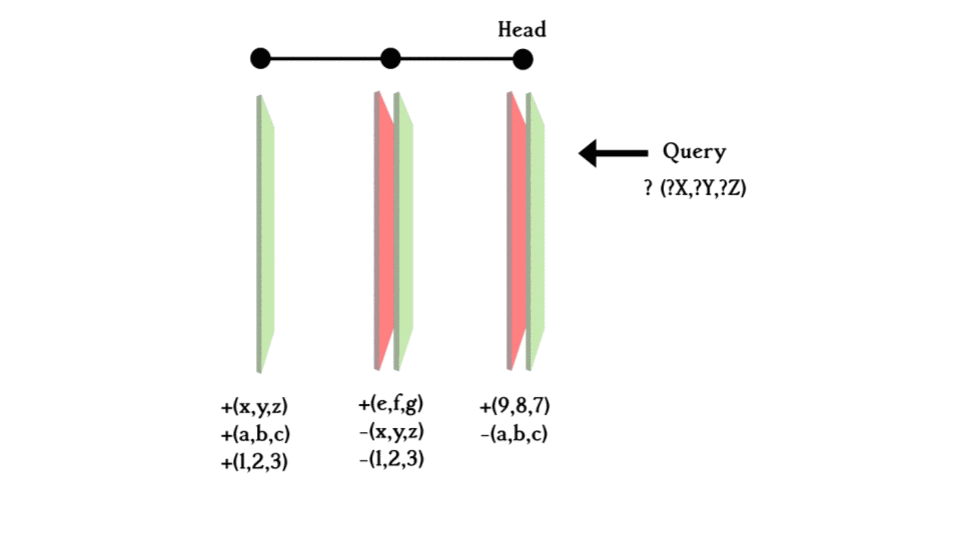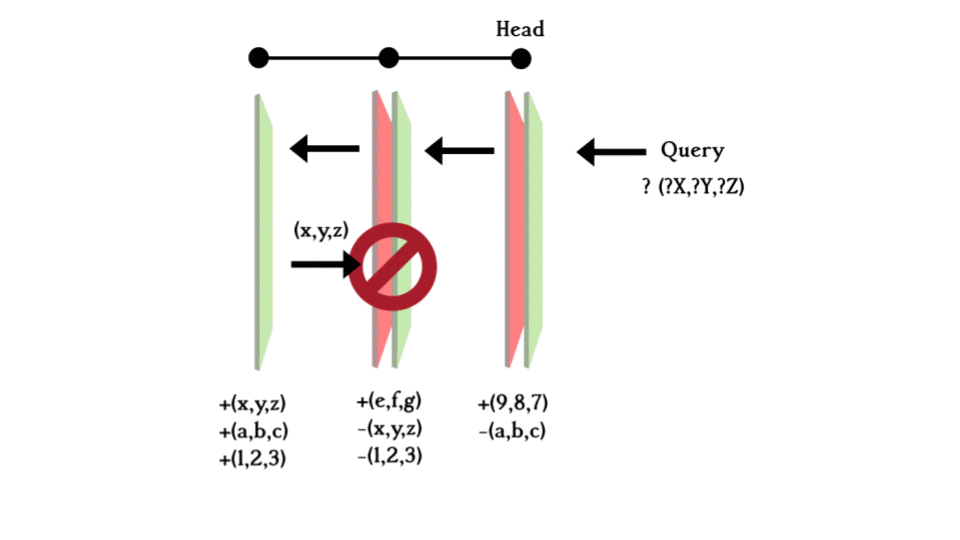
When you make a query, you search from the most recent layer (the HEAD layer) back, if it is found in the +ve plane, it exists in the database; if it is found in the -ve plane, it existed at some point in time but was deleted so it can be concluded that it does not exist in the database anymore. If it is not found on either plane, the query goes one commit back and does the same thing until hitting the initial layer. Concluding whether the exists in the database or not.
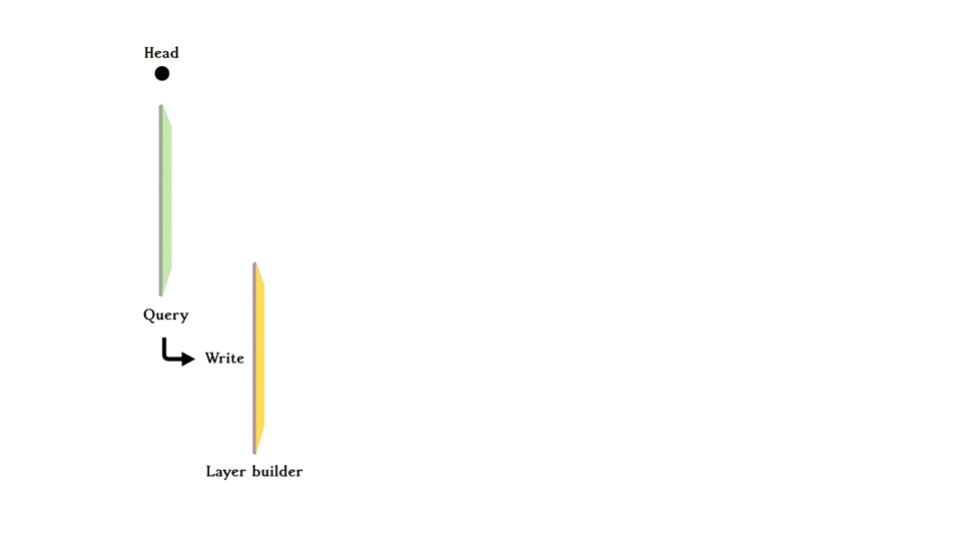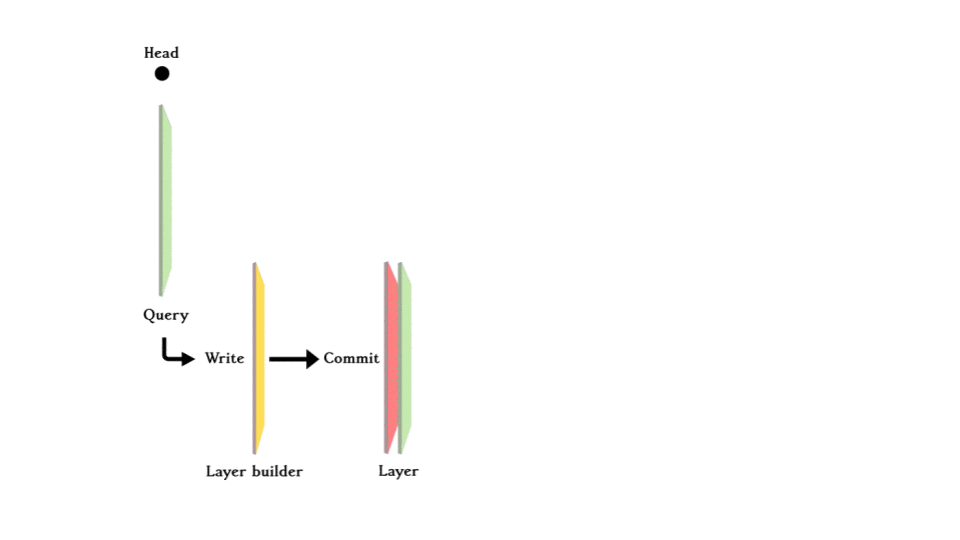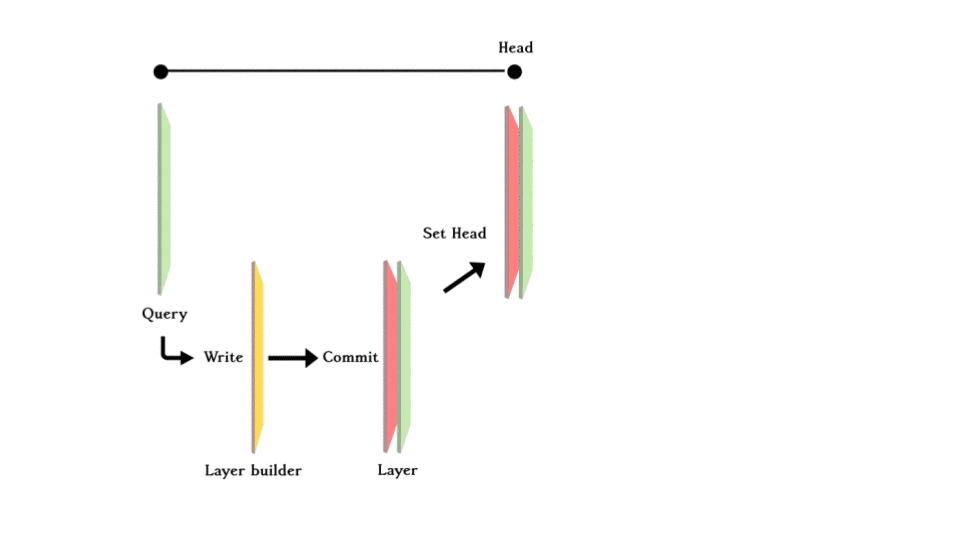
Making changes to the git data in the database is like making a new commit in Git. Internally, a layer builder would build the +ve and -ve plane (except the initial layer) and then commit it to the series of layers, moving the HEAD forward. This makes time travel as simple as moving the HEAD just like Git. Also, imagine you can make a new branch and create more layers and merge it back to the master branch.
There’s so much potential in this genius design. I am already thinking about how this can give many advantages in processing data. I have talked to the team and they are super nice. As the product is quite new, they are happy to answer questions or hear feedback from you.
GitHub: github.com/terminusdb
TerminusDB: terminusdb.com
Discord Community: discord.com/invite/
About the author
This article was written by one of the TerminusDB community who joined us at our Dublin meet-up and later became a Terminator. Cheuk Ting Ho, who we are now delighted to say, is our DevRel Advocate.