
TerminusDB is a powerful in-memory document graph database and provides several enterprise data solutions. It’s packed with features and sometimes the ability to fit into a wide array of applications causes confusion and ambiguity. This article aims to provide a little focus on where TerminusDB provides enterprise data solutions and how it can help data, software, and general IT teams battle some of the complexities of enterprise data architectures.
External data truth and trust
For enterprise organizations to extract meaning from data to make business decisions, it is important to not only analyze the data from within but to also look at external datasets.
Futurist and best-selling author, Bernard Marr, recently wrote a piece for Forbes talking about the importance of factoring in external data to analytics and points to the number of free and premium datasets available today. By only analyzing your internal data, you are looking at the history of events, but not examining ‘why’ these things happened. Looking into market information, weather, competitor activity, and a host of other aspects provides your data scientists with more ammunition to build better and more accurate predictions.
However, external data comes with risks. Everyone on the Internet these days is tooting their horns and giving opinions as statistics. Quite often the same information is available from different sources and these sources conflict. Which one is correct? A machine can’t tell you, well maybe Google’s sentient LaMDA could. This is where some human intervention would help – having a set of eyes on the data, seeing the source, and comparing the information. Using a little human common sense helps improve data import from external sources and aids the business decision-making process.
Enter TerminusDB on horseback, suit of armor glistening in the morning sun. Yes, TerminusDB is the perfect enterprise data solution for this scenario and has several use cases where it has been implemented as an application layer to provide diff and patch functionality for data scraped from the Internet. It is amazing how often data conflicts, one of our customers for example had over 52% of data conflicting from external sources.

Document Translation Use Case
See how TerminusDB replaced a translation business’s in-house approval workflow layer to implement workflow pipelines for translating documents into a variety of languages.
Document Translation Use Case
See how TerminusDB replaced a translation business’s in-house approval workflow layer to implement workflow pipelines for translating documents into a variety of languages.
TerminusDB enables users to compare two JSON documents. The JSON diff and patch functionalities enable manual, user-interface assisted, and client patch operations to let them decide the best course of action for the changes. Users can compare the two documents and decide to accept the original, accept the new version, or suggest a completely new change.
Enterprise data solutions for collaborative application and service development
In code development, distributed and decentralized hosting of Git objects provides immutable, programmable, and highly-available source code repositories. Whenever you clone a repository, you get the whole history, not just the latest snapshot. Software developers have enjoyed these features to work collaboratively to build faster, but the database side of development has lagged. There are a million and one enterprise data solutions to slot into large architectures, but very few take the Git approach to data to provide collaboration and revision control.
TerminusDB adopts a similar approach but for data. Users can clone the production database, make changes, test those changes, and merge them back into production. Much like Git, teams can collaboratively build their data requirements out, review the work of others and test it out before merging. This helps improve quality, speed up development, and also avoid breaking things.
Modern app developers want to use JSON for data architectures and want a native way to collaborate and share data. TerminusDB is a document graph database and the schema language enables documents and their relationships to be specified using a simple JSON syntax. So developers have the simplicity of working with JSON but can still leverage the analytical power of graph relationships.
As we discussed above, TerminusDB also uses a schema, unlike other graph databases. This is great for development to provide a blueprint for building. TerminusDB has another neat utility which is schema driven. The document UI SDK automatically generates customizable user interfaces. The utility takes frames as input and outputs forms in HTML format meaning developers can develop UIs and dashboards directly from the JSON document frames. When an enterprise has a myriad of dashboard requirements and internal and external interfaces bespoke to specific datasets, this feature can radically speed up development time, easing the burden on busy IT teams.

6 reasons why TerminusDB is the right toolkit to build collaborative apps
If you are looking to build collaborative applications where users are a primary source of data and content, then this article explains the TerminusDB and
6 reasons why TerminusDB is the right toolkit to build collaborative apps
If you are looking to build collaborative applications where users are a primary source of data and content, then this article explains the TerminusDB and
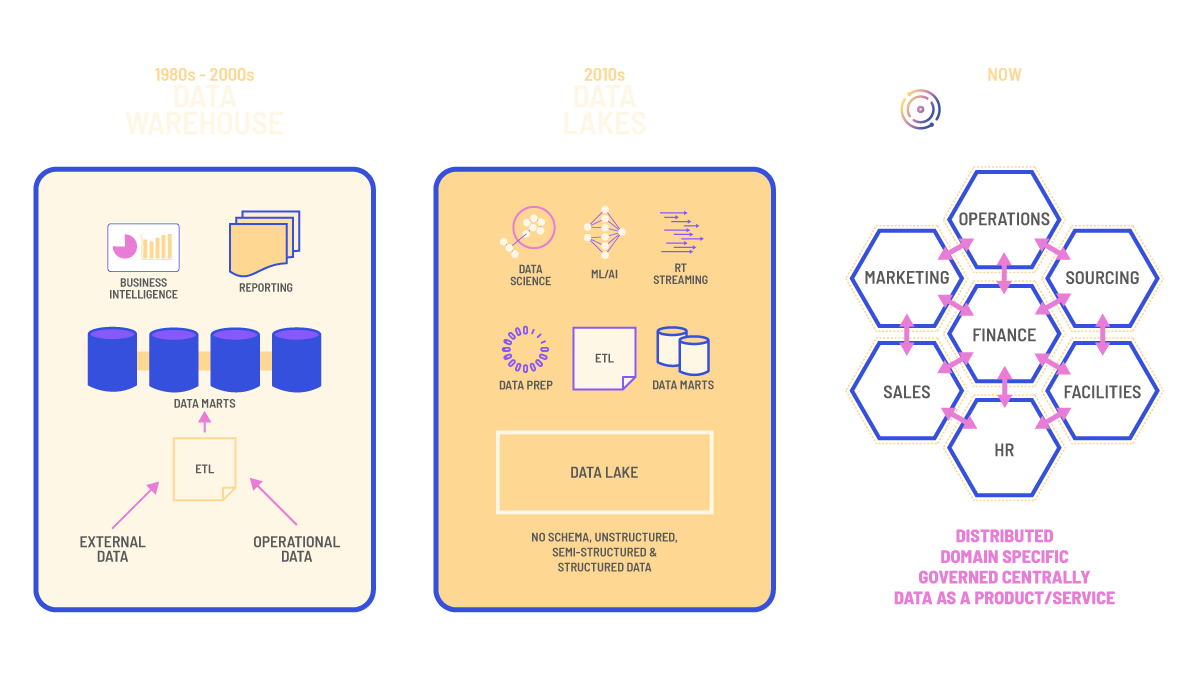
Data as a product
Treating data as a product means getting data to an adequate condition for data customers to consume. That doesn’t mean that it has to be sold, it could be for the wider enterprise business to consume and use within applications or to run analysis. This concept is being embraced by the data mesh paradigm, but changing an enterprise’s whole data architecture is an intimidating prospect, one that could cost millions of dollars and potentially years to achieve. We do believe that for enterprise businesses to stay competitive, moving away from the centralized monolithic is a must and think data mesh could be the answer, however, that is another story.
What is a data product?
You may have heard the term data product being talked about in recent months. We thought we’d take time out to explain what is a
What is a data product?
You may have heard the term data product being talked about in recent months. We thought we’d take time out to explain what is a
TerminusDB is a data product builder. Whether that’s extracting data from the warehouse or lake, application databases, or being used as the database for bespoke projects and applications. Taking a decentralized approach to put projects and domains in charge of their data means that data and context stay bound through the project’s lifecycle. Data accuracy, availability, and reusability are improved by treating data as a product.
As an example, let us look at a marketing department. They use Google Analytics, Social Media, CRM, SEMRush, and sales metrics to try and figure out how to maximize their efficiency. These data sources are disparate and difficult to collectively glean meaning from. With a little assistance from the IT team, the marketing department can build a data product collecting data from all of these sources, and with the UI SDK and TerminusDB’s powerful datalog query language, dashboards and reporting can be spun up quickly to provide business value. Marketing can then see their data across applications to determine which campaigns are working, what influencer activity is bringing in leads, and which email headline brings the most website traffic.
Data fabric
Data fabric is another data architecture framework that has risen in popularity to try and combat the issue of the amount of time it takes enterprises to access and prepare data for use. Data fabric is designed to make data management more agile in a complex, diverse, and distributed environment. It has three key pillars:
- Data catalog/metadata layer
- Knowledge graph and metadata analysis
- Data integration layer
Source data, be it from data warehouses, flat files, XML, or web applications, is cataloged within the data catalog/metadata layer. Connected knowledge graphs with analytics help to activate metadata within the knowledge graph and metadata analysis layer. Within the same layer, AI and machine learning algorithms, enriched with the activated metadata, simplify and automate data integration design. The data integration layer facilitates dynamic data integration for data consumers and is delivered across different styles depending on usage requirements. Data scientists, application developers, and BI developers then have clean and accurate data at their disposal, when they need it.
TerminusDB is perfect for data fabric as it is a graph database using an RDF framework to build knowledge graphs. It is also part of the Singer.io ecosystem which makes moving data into TerminusDB simple. Data is stored as JSON documents and using TerminusDB’s Python client, data scientists can access, query, and do anything they wish with the data to get it ready for experiments. We have some tutorials about the Python client for data scientists here.
The revision control and collaboration features of TerminusDB also provide some added advantages for data fabric. These include the ability to:
- Collaboratively work on the same data assets – Data teams can branch, clone, and merge data to run experiments, make changes, and review each other’s work. This means that collaborative working can prosper to maximize the shared skills within an enterprise data team.
- Revision control provides a base for experiments – The ability to roll back to previous versions of your data means that data scientists can roll back to a specific commit so they can tweak experiments without having to start the process from the beginning. More will be covered on this topic next.
- Schema and metadata branches – Obtaining an understanding of data that doesn’t belong to you can take time. TerminusDB enables the creation of branches for metadata so that anyone using the data can get a better understanding of it, which, in turn, helps improve their usage of it. Additionally, as TerminusDB features schema, this provides structure and a blueprint for those using the data to get a better understanding.
Versioned machine learning
We briefly touched upon versioned machine learning within the data fabric section of this article and we recently spoke to our DevRel Lead Cheuk Ting Ho, who’s an ex-data scientist about this subject. Data scientists within enterprise organizations have it tough, depending on which survey or research you believe, they spend between 50-80% of their time preparing and managing data for analysis. This means they only spend 50-20% of their time using their hyper-specialized skills for the good of the enterprise. Some argue that cleaning data is important, which it is, but we believe that this should be done by people with knowledge about the data’s context and data scientists have skills that are better used elsewhere.
Our long-term goal is to help free this data access so that people working with data get access to quality assets with context quicker, but that’s the TerminusDB future. What we can do for data scientists now is provide them with the tools to be more efficient with their time, make it easier to collaborate with their team, and share their results with the wider business.
As TerminusDB is a graph database, there is a great deal more flexibility in working and modeling data when compared to rigid relational databases. The ability to create your own schema helps to provide a flexible framework to work from and add governance and structure so that data can be slotted into the right areas.
The revision control and collaboration features help data scientists work more efficiently and provide organization to their work. For example, say different scientists are modeling different experiments, they can create bundles to include the model, data preparation procedures, process data, and hyper-parameters (that are difficult to store in a tabular format) from different branches of the same database. These results can then be compared to determine which model is right for the request.
Likewise, branching can be used so that data scientists can deviate to try out different experiments rather than having to double up on the preparatory work. And, if there’s a result that’s not liked, with version control you can roll back and try something slightly different.
The fact that TerminusDB can handle the entire process and store the data, parameters, metadata about the source of the data, and a variety of other details, means that once data scientists settle on a model that works, they’ve got the bundle ready to deploy. They can give data engineers and software developers access to the bundle with all of the information they need to deploy it.
Regulatory reporting
There are thousands of formal risk and regulatory reports that need to be delivered to agencies around the world. Each one needs its own format, its own set of data, and its own language. Without exaggerating, it is a nightmare to manage.
Over the last 20 years, the good decision was often to outsource much of that pain to RegTech providers to build reporting pipelines that delivered an end-to-end solution using your data. There are a few problems with the outsourced approach:
- Very expensive (minimum $250k per annum in licenses and $1 million in implementation)
- Brittle end-to-end pipelines (somebody else’s problem sure, but why do you think the cost is so high?)
- Limited skills retention – there goes the digital transformation dreams
This expensive and difficult dance often acts as a barrier to innovation, it is also a waste of in-house regulatory and technical expertise.
TerminusDB does not give an end-to-end enterprise data solution for regulatory reporting, but it provides all of the capabilities required to build the necessary reporting and regulatory compliance.
- It is an immutable data store, so you can rewind to any report and see exactly what data was used to generate that specific report.
- You get full data lineage – see where the data came from, who interacted with it, and how it was changed
- Every single interaction, by every person, is recorded in the complete commit-graph. Audit requirements in a box.
- TerminusDB is a bitemporal data store, so you have a snapshot at any point in time (end of the quarter) for reporting or regulatory purposes, but if you have updates to the historical data you can also go back and make changes to the data to allow more accurate analysis. Both worlds co-exist. You can replay the data used for the report and you can continue to work on the historical data.
- With regulatory data, you want to be sure that the correct data is being inserted, with TerminusDB you can natively build workflows with approval steps. Once you approve the insertion, the data is merged into the store.
- Get a full knowledge graph of all your regulatory data so you can start to see what is connected. Run connection-oriented queries to look for additional exposures.
- TerminusDB has a full Excel integration – so you can use Excel as your frontend or your ‘head’ – controlled end-user computing
- TerminusDB is SOC2 compliant.

There has been a ‘headless’ revolution in content – regulatory reporting is next
There are literally thousands of formal risk and regulatory reports that need to be delivered to agencies around the world. Each one needs its own
There has been a ‘headless’ revolution in content – regulatory reporting is next
There are literally thousands of formal risk and regulatory reports that need to be delivered to agencies around the world. Each one needs its own
What does the future look like for TerminusDB?
As we’ve hinted throughout this article, we’re not looking to stop at these use cases for developers and enterprise organizations. We aim to create a distributed database for knowledge graphs. One in which you can incrementally grow segments of the graph (data products) over many nodes creating individual high-quality products that are linked at the boundaries and can be shared between nodes. We are building a truly distributed, multi-party, scalable knowledge graph management system. We have recently released TerminusDB v10.1 which we have labeled The Mule. We have added several technical features and performance enhancements, but most of these are all pieces on the way to realizing our broader vision.
Join our Discord to chat with us, or sign up for our newsletter to stay informed. If you like what you see, please give us a star on Github too 🙂