Collaborative Data Ecosystem Use Case
A research collaborative aims to deliver an open integrative science ecosystem to provide the research community with a discovery portal. They aim to provide researchers and academics with access to a wealth of data to use for innovation, experimentation, and adaptation of new use cases.
The project has collaborators from across the globe and involves sharing of different data sources, from automated database updates to data entered manually by scientists and researchers. It is governed by a code of conduct as part of the commitment to promote reproducibility and enhance cross-study comparisons of data through open science and Findable, Accessible, Interoperable, and Reusable (FAIR) data management best practices.
Situation
Before
There are a large number of people contributing to the dataset and data inserted into the database is either uploaded manually or automatically from other data sources.
Inserting data requires custom scripts to be written and due to the fallible nature of code, mistakes often occur. As data is entered into the production database, the errors end up corrupting it. This causes damage and negatively impacts data accuracy with had a knock-on effect on those using it for analysis, experiments, and product innovations.
There is no easy way to undo the damage caused by upload errors and the technical team has to write custom scripts to repair the database so that it meets the strict code of conduct to make it FAIR. This is a time-consuming process that eats up valuable time and degrades trust in the discovery portal.
After
TerminusDB has been implemented as the document graph database for the data ecosystem. It has a number of features to help collaborators upload data accurately in a more time-efficient way.
Schema is used to provide structure to the database and along with the Document UI SDK, data entry forms built directly from the automatically generated document frames make it easy for collaborators to enter information directly into the database. With a quick and easy mechanism to develop user-friendly forms, the need to write custom code is eliminated and the problems associated with broken code are fixed.
TerminusDB’s version control and collaboration features are utilized for computer-loaded data. Branches of the uploaded data are created and from here workflow and approval pipelines are fired off so that the new data has human inspection before merging into production. Any scripts written to transfer data are made easier and quicker thanks to the schema providing guidance, the concise and powerful WOQL query language, and the ability to send data as JSON.
Finally, TerminusDB is an immutable database and creates a commit graph showing every change made in the database. Nothing is ever deleted. It stores these changes as deltas and enables users to traverse the database across time to inspect updates at any stage of the database. This lets users roll back and fix errors should they inadvertently occur.
Pain Points
The research collaborative had the following pain points:
Data entry error-strewn and time-consuming – Having to write scripts for both automated and manual data insertion is time-consuming. Code is difficult and errors creep in that degrade data quality.
No human intervention to assess and approve uploads – Without the ability to check automated or manual data uploads, there is no way to spot and eliminate errors before they reach production.
Difficult and time-consuming to fix errors – Without human checks and custom scripts going wrong, it is inevitable that mistakes happen and data gets corrupted. The time and resources to fix these issues are considerable. Technical teams need to write complex scripts to understand and fix the errors.
Knock-on impact and degraded trust – The research collaborative’s goal is to provide value to those who need the specialized knowledge brought together by the team of experts. When data accuracy suffers this has a knock-on effect on the analysis, experiments, and product innovations that rely on it.
How TerminusDB solved the pain points
With TerminusDB implemented as the document graph database for the research collaborative, the following pain points are solved:
Removing errors from data entry and improving upload efficiency
Schema-led UI design – Although fundamentally a graph database, TerminusDB uses schema to link JSON documents into a graph to remove some of the complexity associated with graphs. The schema also provides guidance and structure for those wanting to build UIs. Together with the Document UI SDK, users can build forms directly from the automatically generated document forms. This means that bespoke forms can be produced and published as an application or webpage for collaborators to manually enter their data. The SDK is quick and easy and enables users to build in JavaScript and style with CSS and JSON. The need for custom scripts is reduced and this considerably reduces data entry errors arising from faulty code.
Approval workflows
TerminusDB features collaboration and version control tools to branch, reset, rebase, and query the database. The ability to create database branches means that changes to schema and the data itself can be pushed into workflow pipelines. This means that computer uploaded data from other data sources, and in bulk, can be inspected and approved or rejected to avoid errors creeping into the database.
Time travel to fix broken data
TerminusDB is an immutable database and creates a commit graph showing every change made in the database. Nothing is ever deleted. It stores these changes as deltas and enables users to traverse the database across time to inspect updates at any stage of the database. This enables the ability to roll back and fix errors should they inadvertently occur. These features save time should anything break and because each update to the database prompts users to provide metadata about it, context is included within the timeline.
Another feature that aids the recovery of the database is TerminusDB’s JSON diff and patch tools that make it easy to compare large JSON documents to see what has changed, and if errors have occurred, apply a patch to fix them.
Total trust
By improving data entry, adding workflow pipelines, and speeding up recovery time, data ecosystem users downstream get a better service and trust the data they use for analysis, experiments, and product innovations.
Results with TerminusDB
The implementation of TerminusDB resulted in improved:
Time and resource efficiency – There has been a 70 percent reduction in time creating, maintaining, and fixing scripts for transferring data thanks to the schema, Document SDK UI, and version control features.
Data accuracy – Due to adding approval workflows and eliminating the need for custom scripts being written for manual uploads, data accuracy has improved with an 84 percent decrease in data-related errors reported in the first few months of rollout.
Availability and reliable services – When errors do occur in the database, which have been drastically reduced, it is faster to remedy the fixes by utilizing the time travel and revision control features of TerminusDB.
User satisfaction – As part of the rollout, a user satisfaction survey was sent to users of the data ecosystem to determine their satisfaction with the service. 97 percent of respondents found the service to be improved and data to be more accurate and available.
Table of Contents
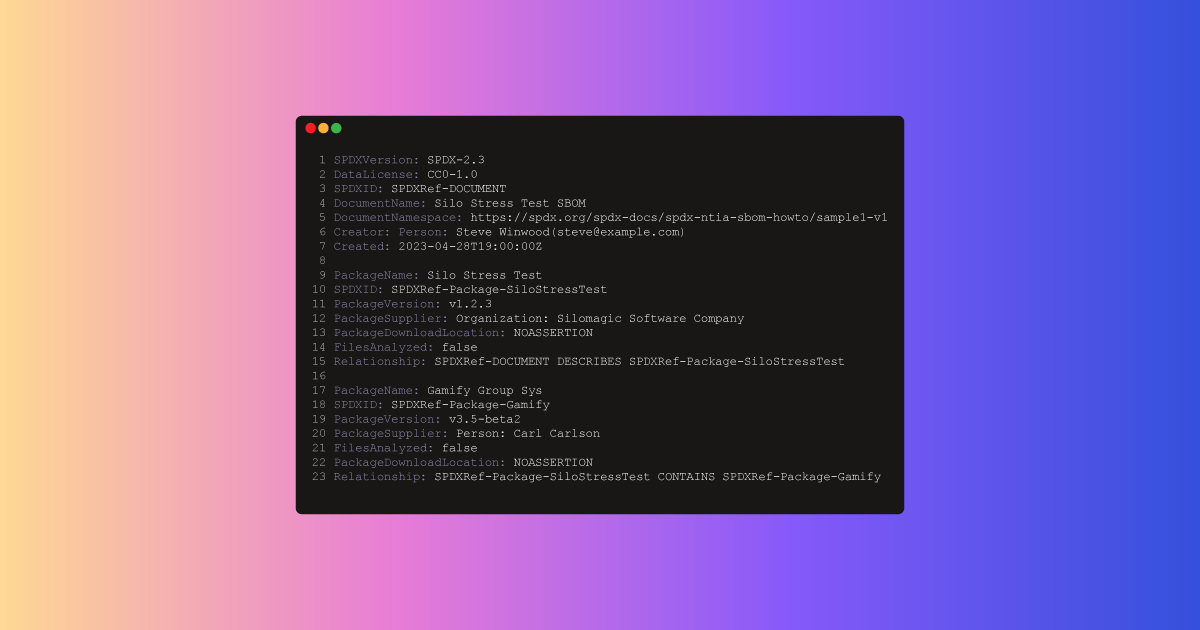
Manage Your SBOM with a Headless CMS
An SBOM identifies, tracks, and maintains a list of all the software components and dependencies, this article looks at how headless CMS is a good solution to manage this process.

Straight Through Processing of Insurance Claims
Using declarative logic and semantic descriptions, we build a low-code app for straight-through processing of insurance claims.
Data Modelling & Collaboration for Change Makers – Do Good With DFRNT
DFRNT is a tool for change makers to model and build data products. With advanced data modelling and graph visualisation, data architects can tackle complex problems.