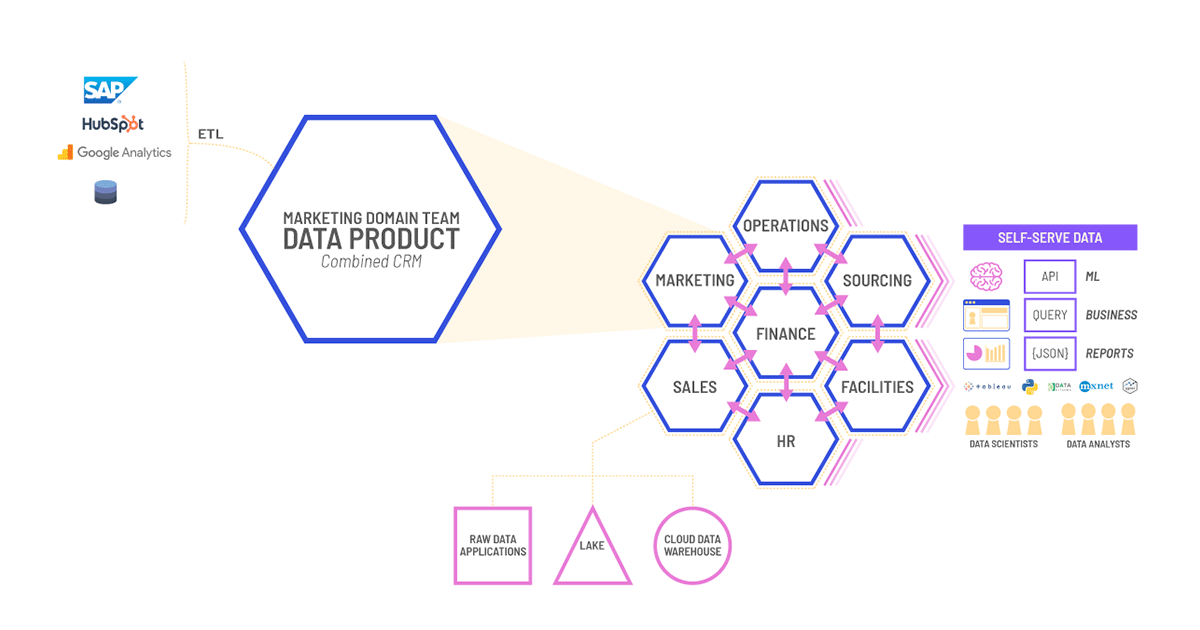
If you have used TerminusDB or TerminusCMS you will know that databases are referred to as data products and this directly correlates with data mesh. Since Zhamak Dehghani coined the term data mesh in 2019, interest in this data management paradigm shift has intensified. In the ever-evolving landscape of data engineering streamlined management, access, and utilization of data is of utmost importance. The challenges of managing and scaling data in data warehouses and lakes have meant data mesh has gained significant traction as an alternative architecture.
TerminusDB – a powerful tool that aligns seamlessly with the principles of a data mesh, offers data engineers an opportunity to revolutionize how they design, build, and deploy data products within a data mesh framework.
This article will explore what data mesh is, how data products fit in, and will explain how TerminusDB is an ideal solution for those embarking on implementing a data mesh architecture. If you’re familiar with data mesh and data products, you can skip the next couple of sections.
What is Data Mesh?
The data mesh framework represents a paradigm shift in how organizations structure and manage their data at scale. Conceived by Zhamak Dehghani, data mesh emphasizes the importance of treating data as a product rather than a mere byproduct of processes. Four key principles drive this approach:
Domain-oriented Ownership
In a data mesh, data ownership is distributed among various domain-oriented teams. Each team is responsible for its own data products, including its creation, maintenance, and evolution. This approach fosters greater accountability and ownership, resulting in improved data quality and relevance.
Data as a Product
Data products are treated as first-class citizens, encapsulating data along with its associated processing logic, documentation, and access mechanisms. This product-centric perspective aligns with the core tenets of TerminusDB, facilitating efficient versioning, collaboration, and governance.
Self-Serve Data Infrastructure
A data mesh empowers data engineers to create and maintain their data products using self-serve infrastructure. This approach reduces the bottlenecks traditionally associated with centralized data management, enabling faster iteration and innovation.
Federated Computational Governance
Instead of a monolithic governance structure, a data mesh employs federated computational governance. This means that each data product team establishes its governance protocols tailored to its specific context while adhering to overall organizational guidelines.
For a comprehensive overview of data mesh, we recommend reading Martin Fowler’s seminal blog.
Data Products in a Data Mesh
At the heart of the data mesh philosophy lies the concept of data products. These are self-contained units of data and logic that encapsulate a specific domain’s information. Data products encompass not only raw data but also the associated metadata, lineage, transformation processes, and access mechanisms. They are designed to be modular, discoverable, and accessible to various organizational stakeholders.
TerminusDB serves as an ideal platform for creating and managing these data products within a data mesh architecture. Its features, such as graph-based data modeling, version control, and collaboration tools, align perfectly with the principles of a data mesh. By utilizing TerminusDB, data engineers can develop data products that are not only well-structured and governed but also foster collaboration among domain-oriented teams.
In the upcoming sections of this article, we will delve deeper into how TerminusDB can be leveraged to build, maintain, and evolve data products within a data mesh, ushering in a new era of scalable, flexible, and collaborative data engineering.
How to Leverage TerminusDB in a Data Mesh Architecture
The most logical way to explain how TerminusDB and TerminusCMS can be used as data products in a data mesh architecture is by working through the key principles of data mesh and explaining Terminus features that relate to each principle –
Domain-oriented Ownership
As previously mentioned, domain-oriented ownership means each team (or domain) is responsible for its own data products, including its creation, maintenance, and evolution. The goal is to foster greater accountability and ownership to improve data quality and relevance.
TerminusDB is structured so that teams have ownership of data products. It is typically structured like this –
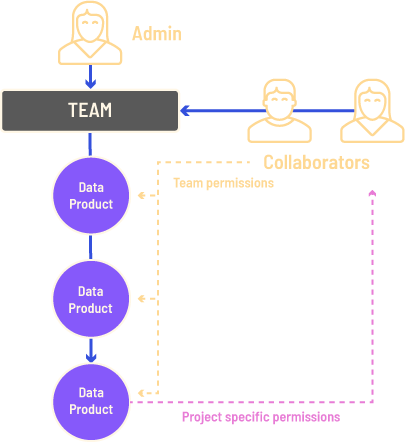
Once a team is created, others can be invited into the team and assigned privileges. They will then be able to access the data products within that team.
Teams will involve collaborators of different technical abilities. Something along the lines of –
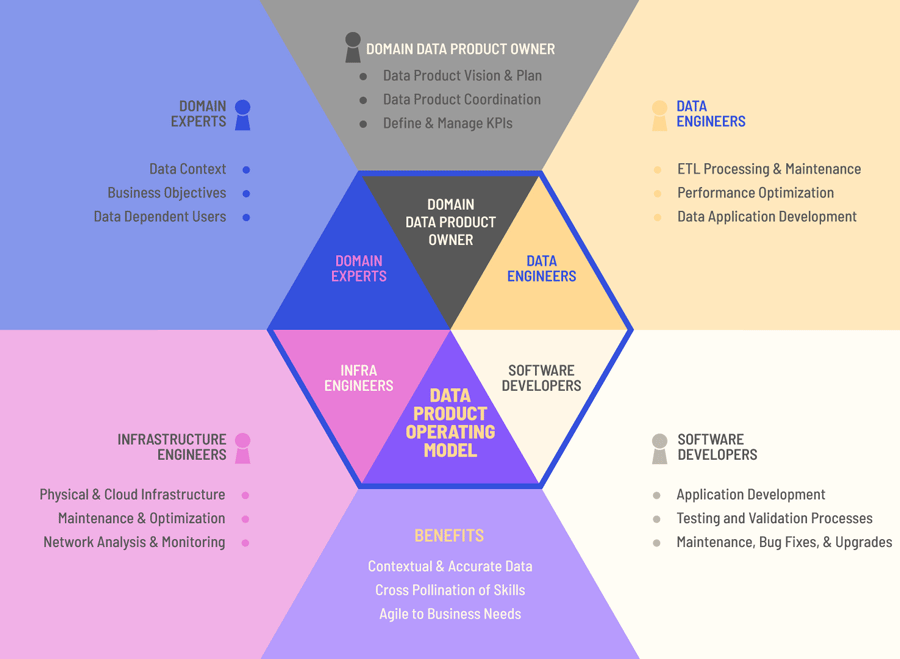
TerminusDB caters to the different needs of a domain team. The Admin UI enables non-technical people to view and curate data. The Admin UI is automatically generated from the data product’s schema.
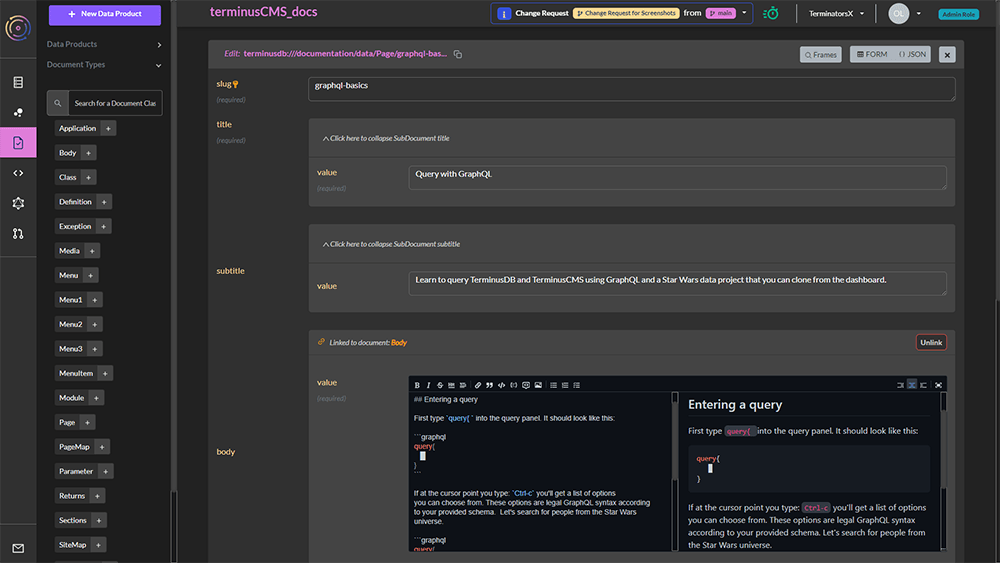
Developers and engineers can interact with data products via a number of interfaces including the command line, and JavaScript and Python Clients through GraphQL and REST APIs.
Data as a Product
TerminusDB data products are document-oriented graph databases that feature several data management tools. Data products use the closed-world assumption to represent knowledge, meaning that every data product is context-bound by its schema. This approach is ideal for treating data as a product. The schema language, based on a simple JSON syntax, means domain teams can define their data models including validation, context with metadata, and relationships.
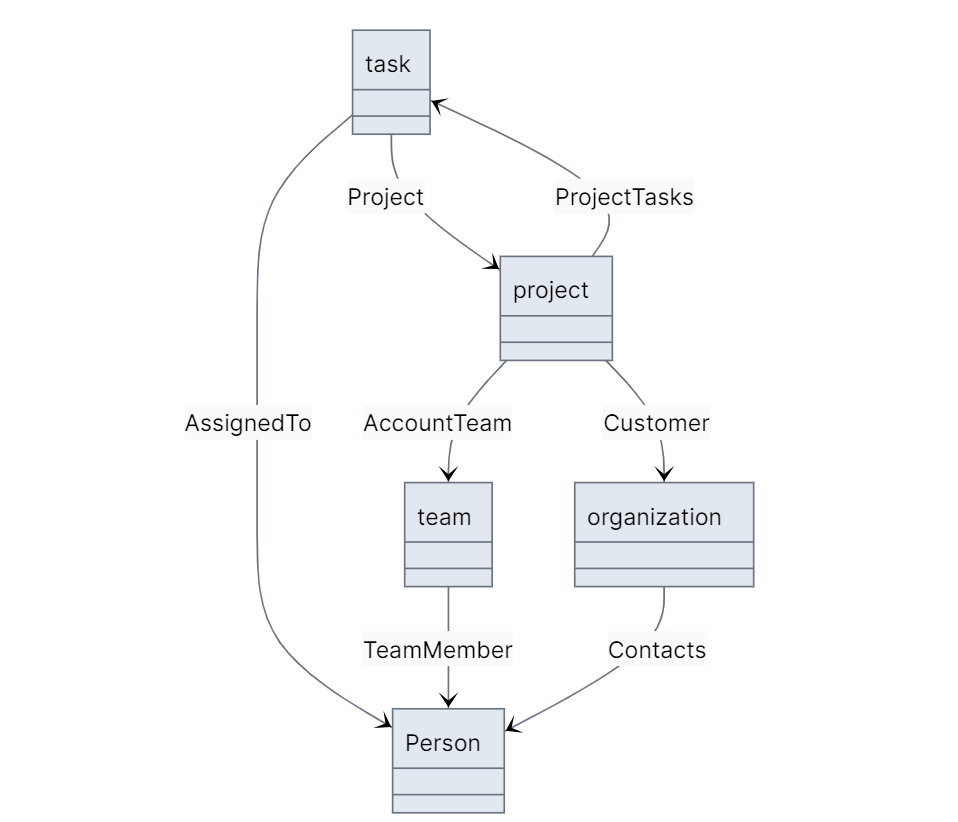
TerminusDB’s schema language uses a Literate Type Theory for JSON that specifies typed references, giving the power of graphs with the simplicity of JSON. Data structures in most languages are easier to match with a document approach and is how JSON as a data format has become a de-facto standard for API integration.
As well as self-contained data products, TerminusDB allows interoperability with other TerminusDB data products. TerminusDB allows storing references to remote data instances using `Foreign` types rather than `Class`. We would recommend not being over-reliant on Foreign types. The more external references a data product has, the more upstream damage could occur should someone make changes without your knowledge. The purpose of data mesh is to move away from complicated pipelines and not end up in the same mess. It is more logical to get the data you need from one or more data products and work with the extracted data.
This brings us nicely to…
Self-serve Data Infrastructure
TerminusDB is essentially a headless data management system for knowledge graphs, think of it like a CMS for data. With it, domain teams can model and curate quality data, in often complex environments, for consumption. Data input and output are JSON making it straightforward to programmatically import data from applications and services, as well as accessing the data to power front-ends and analytics.
Data can be queried, added, amended and viewed using REST and GraphQL APIs. It also features a powerful Prolog-based Datalog query engine called WOQL for advanced analytics of data products.
With some clever tinkering under the hood, GraphQL schemas are automatically generated from the data product schema providing graph query capabilities using the API language. This makes it far easier to do advanced path queries and for other domains to help themselves to the data they need.
query{
People(filter:{label:{eq:"Chewbacca"}}){
label
_path_to_People(path:"(film,<film){1,2}"){
label
}
}
}
Non-technical users can find the information they need using the Admin UI, and front-end developers and data scientists can work with JSON.
Federated Computational Governance
Governance of data mesh is often the major sticking point with advocates of monolithic architectures. The worry is that by having many data products, applying appropriate governance is a logistical nightmare, ineffective, and a resource drain.
Monolithic architectures aren’t brilliant for governance either, hence the rise of data mesh. In a centralized environment, implementing governance policies and standards can become convoluted. A one-size-fits-all approach may not address the specific requirements of different data consumers, leading to compliance issues and dissatisfaction.
One of TerminusDB’s distinguishing features is its collaboration model. TerminusDB is immutable and keeps versions of everything in an extremely compact delta format (succinct data structures). Because all versions are stored, TerminusDB can query any past or present commit. Each data product in TerminusDB is actually a collection of graphs that not only track your data but important information about your data.
Features, in TerminusDB’s database layer, that are essential for federated computational governance include:
- Change management – Changing schemata and data can be dangerous. TerminusDB change management tools include change requests and approval workflows. A change request opens up a branch of a data product for changes to take place away from live data. Conflict checks and reviews must take place before any changes can be merged.
- Data lineage – Every change, human or machine, is stored in the commit graph showing who changed what and when.
- Time travel and document history – See the complete history of any document and a snapshot of what your data products looked like in the past.
- Diff – A diff takes two JSON objects, or two branches, and presents any differences between them. A key use is displaying a clear summary of differences between large objects, enhancing the visibility of changes. This enables manual or user-interface-assisted action to resolve changes.
- Revision control – TerminusDB is like Git for data with revision control for data management. Data products can be cloned, branched, and merged, with the ability to roll back to a previous commit should anything go awry.
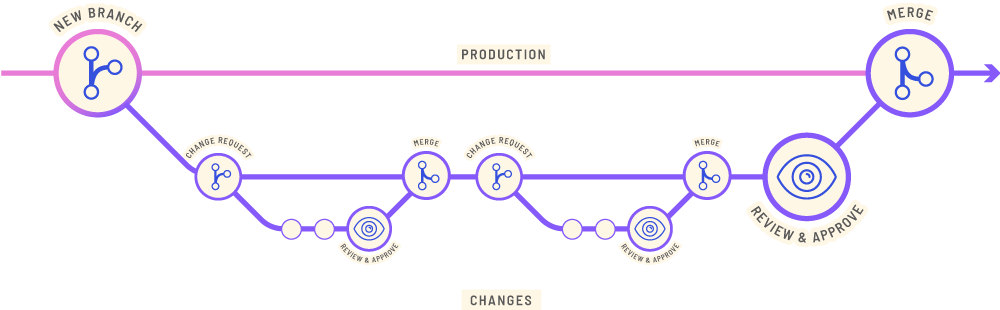
The collaboration model coupled with a standards-based approach, JSON and RDF, help to ensure –
- Overarching governance for data products in the data mesh
- Flexible domain data governance
- Data product interoperability
- Data quality and accuracy
- Data ownership and accountability
- Security and privacy.
A Cultural Shift rather than a Technical Shift
While we have been talking about product functionality, it is important to note that data mesh is not really about the technology, it is a cultural shift in the organization. One where there needs to be a buy-in from all relevant stakeholders.
Data mesh transforms how organizations view and collaborate around data. It encourages domain-oriented teams to take ownership of data products, fostering a culture of accountability and collaboration. This emphasis on decentralization, self-service, and cross-functional collaboration challenges traditional data silos and promotes a cultural change that aligns teams toward a shared data-driven mission.
TerminusDB comes with features to enable cross-team collaboration and domain ownership of data products, but in order for these tools to help, effective communication and project leadership needs to pave the way for organization-wide buy-in and cooperation.
Are you on a Data Mesh Journey?
While the data mesh architecture offers numerous benefits, it might not be suitable for every business scenario. Smaller organizations with limited data complexity and a tight-knit team might find the overhead of implementing a data mesh outweighs the advantages. Similarly, industries that demand strict regulatory compliance or deal with highly sensitive data could face challenges aligning the decentralized nature of a data mesh with their governance requirements. Additionally, businesses where data integration is not a primary concern, such as those with simple data flows and well-defined processes, might find that the complexity introduced by a data mesh is unnecessary for their operations.
The data mesh approach is particularly advantageous for large enterprises dealing with diverse and complex data landscapes. Businesses that aim to scale rapidly and need to accommodate a growing number of data sources, domains, and use cases can benefit from the flexibility and modular nature of a data mesh architecture. Furthermore, organizations seeking to foster innovation and collaboration across cross-functional teams by treating data as a first-class product will find that the principles of a data mesh align well with their strategic goals.
If you are starting your data mesh journey, consider TerminusDB and TerminusCMS as a data management platform for self-service and well-governed data products. Try out TerminusCMS and join us on Discord to ask any questions or chat with our dev team.