

GraphQL CMS – Why GraphQL is a Must Have
A GraphQL CMS is efficient at fetching and retrieving data & our graph query ability is a must-have for those building content infrastructure
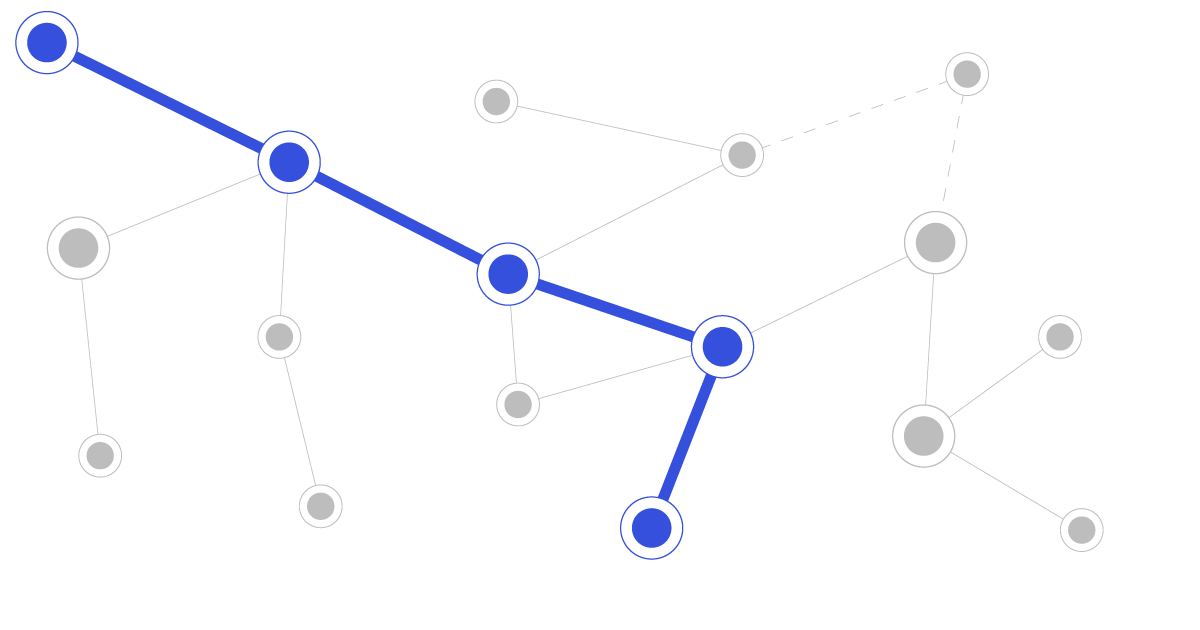
Putting the Graph in GraphQL Query
GraphQL is neither graph nor query language. It is great, but we wanted to use GraphQL as a graph query language so we did something about it.

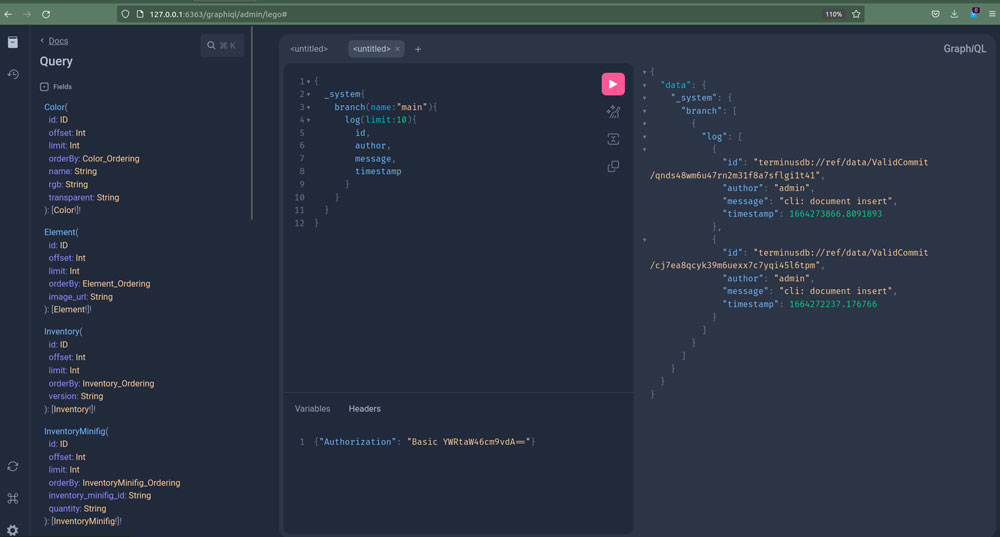
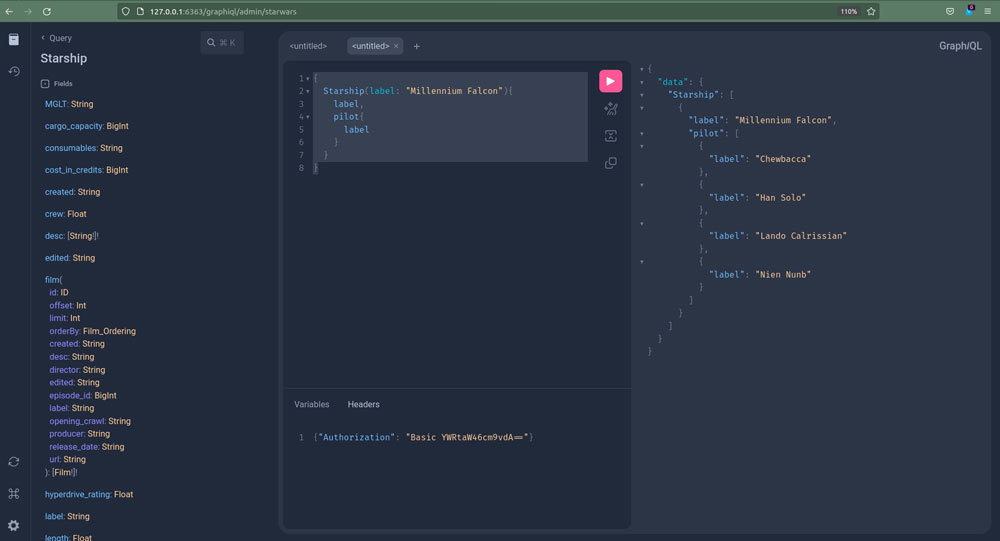
GraphQL RDF Bridge using Star Wars Dataset in TerminusDB
I wrote this blog to showcase a GraphQL RDF bridge using a Star Wars dataset that I found. It explains what I did in TerminusDB
GraphQL CMS – Why GraphQL is a Must Have
A GraphQL CMS is efficient at fetching and retrieving data & our graph query ability is a must-have for those building content infrastructure
Putting the Graph in GraphQL Query
GraphQL is neither graph nor query language. It is great, but we wanted to use GraphQL as a graph query language so we did something about it.
GraphQL RDF Bridge using Star Wars Dataset in TerminusDB
I wrote this blog to showcase a GraphQL RDF bridge using a Star Wars dataset that I found. It explains what I did in TerminusDB