Putting clean, versioned data in the hands of the people that matter: your business units.
Forbes predicts that more than 150 zettabytes of real-time data will need analysis by 2025. But it’s not just about volume. Much of the data is unstructured and coming from multiple sources. The same article notes that over 95% of companies require help managing these datasets.
Data warehouses and lakes have been overwhelmed by information, with users experiencing enormous difficulty simply finding what they need. According to ThoughtWorks, Enterprise Data Warehouse initiatives have a higher than 50% failure rate. Not a lot of production for such an expensive infrastructure (A typical data lake, according to Amorphic Data, costs anywhere between $200K–$1M.)
The problem is that even though the data is in one place, it’s still difficult to extract information from individual siloed locations into a central database, resulting in huge backlogs. There’s also the complication that if there are any issues requiring cleaning in the warehouse, it’s an extremely long process, delaying everything further.
But perhaps most important is the fact that these central IT teams, the ones overloaded with huge backlogs, really don’t have the best knowledge of the data content. That knowledge belongs to individual domain leaders.
If you’re in sales and marketing, you need data around product performance, revenue scale, revenue per account, customer acquisition efficiency, customer lifecycle, sales efficiency, margins, pricing and channel analysis—a host of metrics that you understand a lot more than the central IT team.
If you are in Ops, Finance, or HR, the data, the content, and the narrative will all be equally granular and look completely different from other departments. Each domain team understands its own data better than anyone else. And those domain leaders should have access and views for all of their data. After all, it’s their data!
With this access, they have the ability to craft data into a narrative, pulling metrics from other departments if necessary, and publishing a coherent analysis of their team’s status.
These domain leaders—the ones who answer business questions—need to come first. What is needed is a distributed and decentralized structure that empowers these teams to employ their data to deliver the best outcomes.
Leveraging the Data Mesh
To accomplish a distributed and decentralized structure requires moving from a centralized paradigm of a lake or warehouse to a modern architecture: data mesh. According to Barr Moses, data mesh “is a type of data platform architecture that embraces the ubiquity of data in the enterprise by leveraging a domain-oriented, self-serve design.”
Zhamak Dehghani, Thoughtworks Director of Emerging Technologies, describes the building blocks of a ubiquitous data mesh as a platform as “distributed data products oriented around domains and owned by independent cross-functional teams who have embedded data engineers and data product owners, using common data infrastructure as a platform to host, prep and serve their data assets.”
The key is this domain-oriented data ownership and architecture—with the data in the hands of the business units (domains). This is especially important in extracting value from analytical data and historical facts.
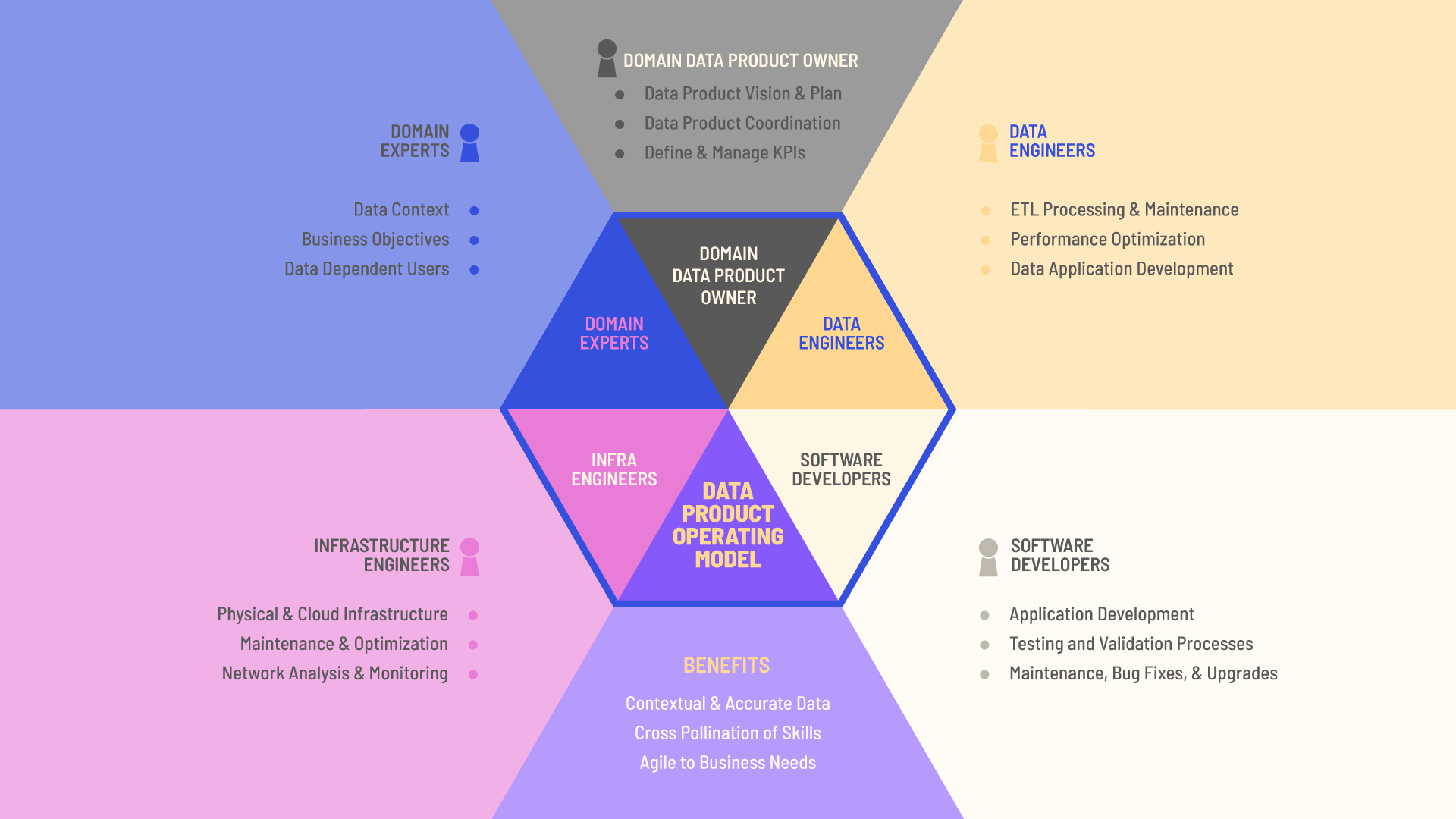
Once data has been distributed to domain leaders, concerns around accessibility, usability and harmonization arise. This, says Zhamak, is where product thinking is critical: “Domain data teams must apply product thinking with similar rigor to the datasets that they provide; considering their data assets as their products and the rest of the organization’s domains, data scientists, ML and data engineers as their customers.” When business units begin treating data as a product, the reward is “a distributed data architecture, under centralized governance and standardization for interoperability, enabled by a shared and harmonized self-serve data infrastructure.”
Departmental Data Access
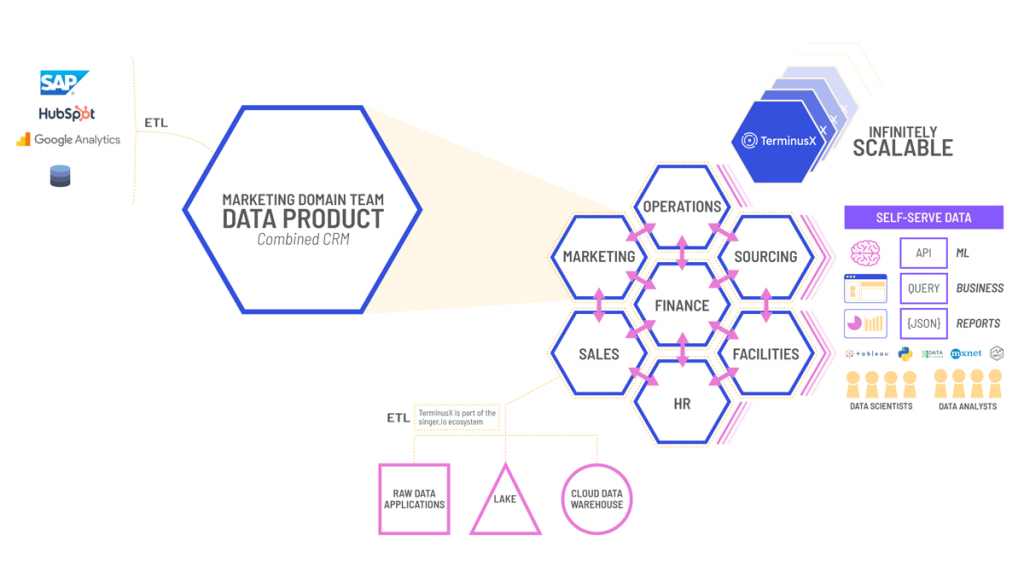
TerminusX is a self-service data platform that allows you to build, deploy, execute, monitor, and share versioned data products. TerminusX versions both data and schema, allowing your team to deliver a consistent product—while improving and innovating. Your data is decentralized and can be utilized by those who need it.
With a decentralized data mesh platform, data moves from overburdened IT to the departments that need it the most. Product, sales, marketing, ops, HR — all have their own view. And these domain experts have the speed and agility to use their data to make decisions and improve applications. No longer is marketing waiting for historical campaign numbers from an overworked IT team. No longer is the new campaign on hold until they get their data.
To eliminate these bottlenecks, TerminusX enables the marketing team to build self-service data products, including all current and historical data, as well as relevant data from other departments in a data mesh architecture.
With the amount of data in enterprises today, collaboration is key. Building new customer applications, improving internal processes, increasing predictive analytics all require flexibility and access not available on centralized monolithic platforms.
Version control, which is at the heart of TerminusX, is the key to effective collaboration. With version control, you can access, share, and work on multiple versions of the same asset at the same time, all in a controlled, optimized way.
Data decentralization and distribution powers continuous change and scalability and lets your productive teams work at a fast pace, not slowed by the ‘centralize everything’ ethos of legacy architectures. Each domain can expose one or many operational APIs, as well as one or many analytical data endpoints. The data mesh architecture supports the autonomy of your domain teams.
Perhaps best of all, TerminusX can be tested with little to no risk. It can be implemented on discrete data sets initially, and can be quickly scaled as needed—a process simply not possible on monolithic, centralized platforms. In addition to mitigating risk, this also significantly speeds development time, and allows you to scale where you need it, when you need it.
How it Works
TerminusX is powered by TerminusDB, a database which uniquely combines the power of knowledge graphs with the simplicity of documents. This means complicated documents (with say an internal structure and sub-documents) can all be connected in custom ways.
Why is this important for data? Say you have an inventory system that you want users to access, but you also want to ensure that the records in it are reviewed, corrected or run through an editorial process. Today this is done in a haphazard way, where people edit in a live transactional database—something you’d never do with code. TerminusX solves this, moving data into the same development and deployment process that has revolutionized software. Versioning and branching data has many other uses too, you can create bitemporal datasets and withhold certain information and make them available to other stakeholders, such as regulators, customers, or other teams.
Knowledge Graphs
TerminusX allows you to build a distributed knowledge graph made up of a vibrant ecosystem of interoperable data products. By harmonizing internal and external data relevant to your organization you can improve operational efficiency for the enterprise and competitive advantage for the business units. The fundamental advantage of knowledge graphs is that they model the world as things that have properties and relationships to other things. The knowledge graphs that companies like Google and Facebook have accumulated are demonstrably commercially powerful and it is unlikely that such complex and rich datasets would have been possible without a graph. TerminusX allows you to model your data with properties and relationships to build a bigger picture to drive operational efficiency and service innovation.
Commit Graph
The TerminusX database records and tracks all versions of data, enabling live query at every version, at any point. This covers the whole data lifecycle – you can audit any change with a full commit history. And the versioning is not only linear — you can almost instantly branch to another database and create a new timeline that shares the timeline of the new database. The commit graph, which clearly shows who updated what and when, can be valuable to management, and can assist with compliance requirements. With the Commit Graph, TerminusX also significantly reduces compliance and audit costs.
Use Cases
Tamper-evident data audit
Audits are laborious, expensive and subject to rigorous legislation and standards. The requirement is for extremely detailed documentation over time, a full accounting of records, reports, operating practices, and documentation. TerminusX records all changes to your data, giving you a full, immutable audit log. In your existing data infrastructure, you can add new versions to existing records, but the database never changes or deletes records. This lets you store critical data without fear of tampering and provides proof of data inclusion and historical consistency in real time.
Regulatory and compliance demands
A new DeLoitte article points out that “the pace of regulatory change, convergence in global regulation, and competition from new market entrants…have created a complex environment for compliance leaders across all industries.” TerminusX helps you to meet compliance challenges by providing detailed data lineage, flexible data modeling, and performance capabilities. You can now give regulators a snapshot of the exact situation at any point in time.
Data management
In a recent whitepaper, KPMG points to incorrect data being a huge data management problem plaguing organizations today: “Businesses lose massive amounts of money each year by basing their decisions on bad data…it is essential to have appropriate data quality processes in place to ensure decisions that are based on complete and accurate data.” TerminusX delivers just this: now your domain teams can leverage product thinking to improve your data management, provide a holistic customer view, and manage risk across multiple domains.
360-degree customer view
In a recent report, Forrester notes that “ customer service organizations must accelerate their adoption of AI-powered self-service technologies for frictionless service.” To genuinely improve the customer experience, AI is critical to develop valuable context across customer data. TerminusX provides the ability to seamlessly employ multiple data products from current and historical trends, to build a customer view with superior context and quality.
Supply chain analysis
Supply chain risk management is the discipline of identifying, assessing, and mitigating supply chain risks. A TerminusX knowledge graph enables this detailed analysis with a distributed knowledge graph made of interoperable data products. By harmonizing internal and external data relevant to your organization you can quickly identify any weak links in your supply chain.
Traceable data lineage
TerminusX is an immutable data store, tracking every version of every piece of data. The commit graph delivers the ability to monitor inventory, parts, cost control, and KPIs related to audits across the supply chain. You can access data remotely, maintain stakeholder data, and unify related concepts using your data model. This new agility enables you to rapidly respond to business changes and new requirements, easily including new data sources.
Predictive analytics
Whether you’re using predictive analytics for marketing or ops optimization, fraud detection or risk reduction, TerminusX allows you to leverage graph analytics to improve the quality of the data going into your predictions. Equally important, version control allows you to capitalize on all your valuable historical data to make the best decisions. TerminusX’s end-to-end prediction pipeline accurately identifies the likelihood of future outcomes—based on all of your data.
Conclusion
With TerminusX, you reinvent your teams’ ability to leverage data. Now your organization is:
- Agile,with domain teams working in interoperable but containerized ways, deploying when they need to.
- Scalable, so you can create new data products whenever new data appears.
- Accurate, since data product responsibility lies with the producers and experts.
- Self-serve, allowing business teams to create fully end-to-end, automated deliveries.
- In Control, with metadata, provenance and audit history with data lineage.
With TerminusX you are fully utilizing your data – in the hands of the people who know what to do with it. Now your business units are able to innovate with data products, employing improved service, applications, processes, reporting — and lower costs.
Best of all, it happens in just a few clicks.