
This article talks about the Seshat Database, a knowledge graph providing meaningful data about all human societies.
The history of the world sounds amazing and unimaginably massive.
Thanks to academics and scholars, we know a lot about the life of our ancestors, and thanks to the progress of technology, we now have lots of open data available on the internet. This data helped build the Seshat database. To gather and organize a knowledge graph covering large-scale human social evolution, however, is a huge challenge.
Seshat: Global History Databank
Named after the Egyptian goddess of wisdom, knowledge, and writing, Seshat, the Global History Databank aims to bring together the most current and comprehensive body of knowledge about human history in a human graph.
Researchers divided the world into a series of Natural Geographic Areas and collected datasets describing all of the specific historical societies or polities (an organized society; a state as a political entity) that had existed in those areas. By storing the data in a systematic way, different hypotheses about the rise and fall of large-scale societies across the globe and human history can be tested.
Here are some facts about the data in the Seshat database project:
- Academic collaboration seeking to create datasets describing every human society since 10,000BCE
- Major publications in 2018–19 in Nature and PNAS on the evolution of social complexity and religion based on a high-quality RDF DB
- Sprawling collection of datasets covering 1000s of variables, mostly human entered and error-prone, with a wide variety of formats and schemata
In 2018, the Seshat researchers released several public datasets that can be found here. The challenge Seshat faced was finding a proper tool that can store the databank in a semantic way that lets researchers query, analyze, and collaborate with the data.
TerminusDB: Building the Git-like Seshat Database
Named after the Roman God of boundaries, TerminusDB is an open-source database that provides structured, semantically meaningful data for the rapid delivery of data-driven applications.
With TerminusDB’s unified OWL model, a semantic schema was created to capture all the complex aspects of the Seshat historical data model. We then wrote queries to ingest data and build an integrated knowledge graph.
Based on an immutable append-only MVCC in-memory triple-store, implemented in a custom rust storage library, directed by a Prolog logic engine, the Seshat database is efficient, safe, and allows Git-like operations – push, pull, clone, merge, and branch. With these advantages, multi-mastered cloud databases can be used to build automated pipelines for low-cost data publishing and distribution.
All of the Seshat Database functionality was achieved easily with WOQL, the Web Object Query Language. It is a powerful language for querying the structure of TerminusDB Data. It can also be used to construct the schema and load data into the data graph. WOQL is also available in JavaScript client (WOQL.js) and Python client (WOQL.py) which allows programmatic operation of data and smooth integration of analytic and machine learning pipelines and applications.
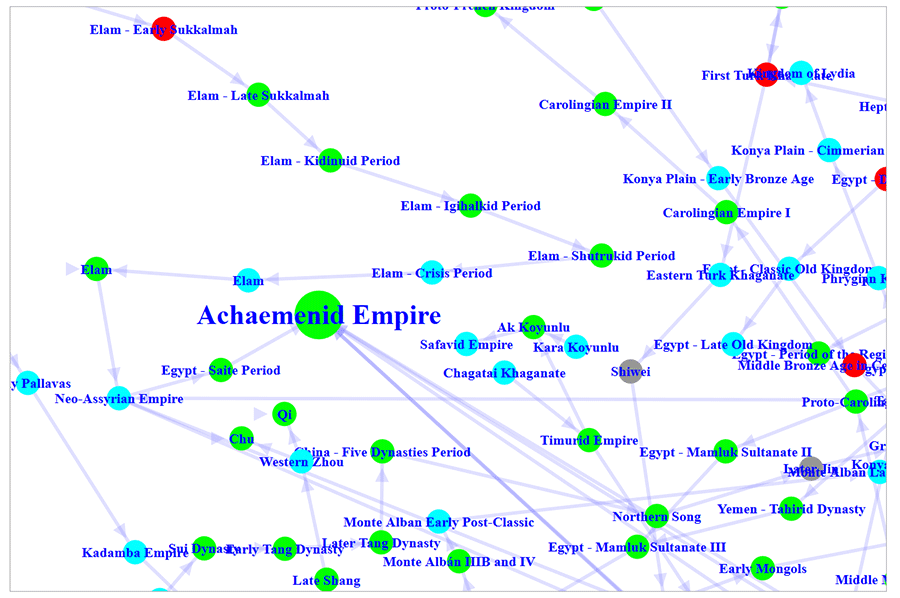
We used WOQL to ingest all of the Seshat data into a great big knowledge graph and then generate graphs showing the evolution of hundreds of different properties of historical societies as they changed over time.
The above graph shows all of the global historical timelines in Seshat, with each node representing a polity and the edges showing the ‘successor’ polity, the colour of the nodes represents the presence (green) or absence (red) of professional soldiers in each society.
Stay tuned as we will soon be publishing a detailed tutorial showing you how you can build your own knowledge graph using TerminusDB and the Seshat dataset.
Design a Query Language Client for Pythonistas and Data Scientists
If you want to know more and to stay up to date with community events and other things happing in the data world, sign up to our newsletter or follow us on our socials.