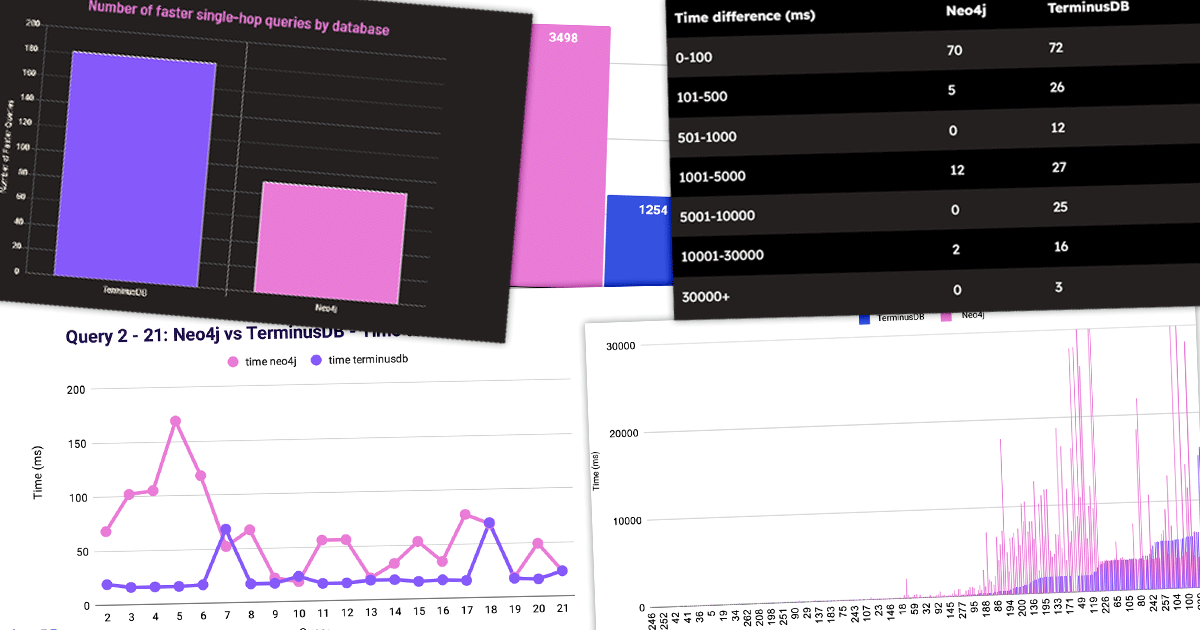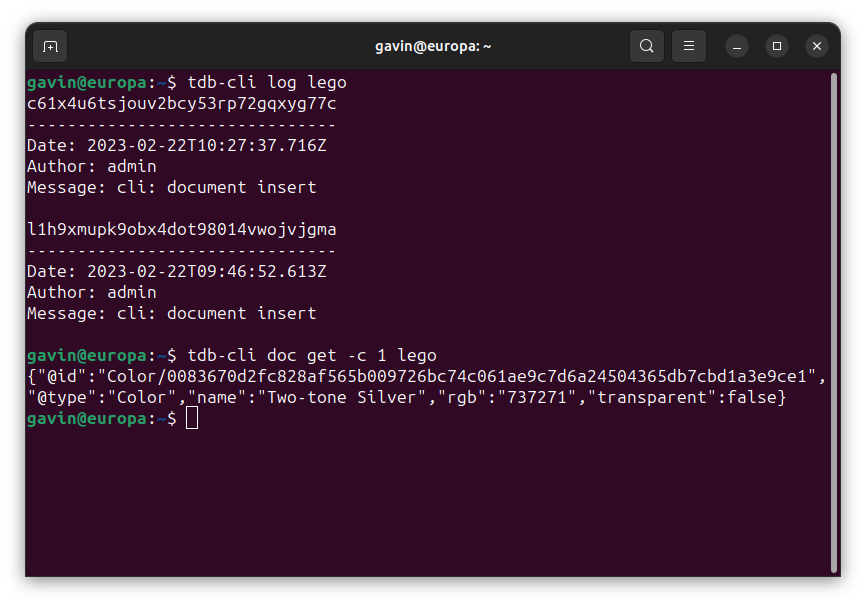


Managing Databases in a CI/CD pipeline is a nightmare. Migration scripts are better than making changes on running servers, but become hard to manage in complex modern pipelines. Truly solving the problems requires revision control for databases so that you can clone, branch and merge your database.
Devs have it pretty good these days.
With Git, CI/CD, Infrastructure as Code, and the Public Cloud, you can have an idea in the shower, write some code after breakfast, commit to git and start collaborating with colleagues after lunch.
You can Docker up your app, Terraform some infra, create a CI/CD pipeline, and then test and have everything deployed to production by dinner.
By beer o’clock you’re sitting back and watching the hype buzz up the ranks on hacker news.
But then, after the glorious intro to this thus-far happy film, our protagonist wakes up screaming.
What horror haunts their dreams? What nightmare invades their peaceful bliss? What terror wrenches their face into a wretched scowl?
It’s The Data!
It’s the damn database.
Every application is perfect, beautiful, flawless, until you have real users and their stupid data. Then, the pain begins.
Then, when you want to push more amazing code to production, the database rears its ugly head, raises its iconic knife-fingered glove and sneers “Come to Freddy!”
As I was saying, managing Databases in a CI/CD pipeline is a nightmare.
Git, CI/CD and Cloud APIs have completely transformed the way software is made. The days of slow and deliberate software release with loads of manual work are gone, we now live in a world of continuous everything as code.
However, once an application is live, it has production data. Production data is important, especially to users, and needs to be preserved, you can’t just wipe it out when you release a new version of your software to production, and the new version of your software has schema changes and new data.
In the old days, when software changed such that the database schema also had to change, DBAs would immediately wait around for a few months, mostly hiding, until eventually, several entity–relationship diagrams later, they would simply take backups, modify the schema on the live server and hope for the best.
Since new software was deployed less often than Sylvester Stallone movies were released, and users were fine with a few hours, or even days, of downtime for each update, everything was fine. In those days “Agile” was a word you used to describe a Soviet gymnast, not a software development team.
But now, applications are developed continuously, different versions of the application need to run in test, dev and staging environments, each of which has different data and a different schema. This makes for a difficult set of challenges in the set up of each environment, and the reliable promotion of software from one environment to the next.
Moving data to production requires not only updating the databases schema with the latest changes, but also updating all existing data such that it is valid within the new schema.
Staging environments need copies of production data in order to test things properly. They also need all the new data and schema changes that are required to make the new version of the software work.
So now you’re moving data and schema changes back and forth, up and down the pipeline. But unlike with software source code, you do not have Git to clone, branch and merge your changes.
You need to do migrations. And migrations are flaky, slow, error prone, and frankly, terrifying. The only good thing about a migration is that you can store it in version control with your code.
Writing migrations as code become popular in the heyday of Ruby on Rails, they had “up” and “down” functions, which could either migrate the schema of the production database to the current version required by the software, or revert to the previous version.
Writing up and down migration functions for each schema and data change was a lot of work, but it seemed manageable, and everyone was happy enough so they got back to riding around on single gear bicycles and making fun of DBAs.
Later, clever devs working with enterprise teams at ThoughtWorks and other places, took a break from writing drab Java code and realized that “down” migrations never worked when you needed them, because new data could not be cleanly mapped back to an old schema without losing data. They stopped making them, creating “forward only” migrations, only making “up” migrations, and if/when they needed to revert, they would just make a new migration. Forward became the new back.
It all seemed peaceful enough. But then devs everywhere started seriously hating on monolithic software. Armed with JavaScript and enjoying their single origin coffee, they decided that one schema was not enough, because with microservices, feature flags and various roll-out strategies, not to mention multiple versions of mobile apps, you couldn’t just go forward. You needed to support multiple versions of your schema at the same time, and the expand and contract pattern was born. You “expand” outward, adding new tables and fields, but leaving old ones for older versions of your code, or platform. Then, when you’ve sunsetted the older versions or API endpoints, you “contract” and delete what you no longer need. Except you don’t – you forget, or you never sunset older versions. All of this becomes unmanageable quickly and productivity grinds to a halt.
It’s a lot of work, and as applications become more data-centric and designers create design systems with all kinds of amazing reactive components for devs to use in their applications, each of these components has fields and each of these fields have data, and this data needs to be stored in a database, and this database needs to updated every time new components are added, modified, or used in new ways.
And so here we are. Stuff is complicated. And despite all the awesomeness of devops, design systems, CI/CD, infrastructure as code, despite all this automation, everyone is still terrified of the production database.
How we do we deal with all this?
If only we could manage the revision of data the way we manage the revision of our source code. If only we could just merge our latest changes into the production database. If only we could simply clone our production database for staging, if only we could just push changes from a developer’s local machines to a test environment!
If only … we had something like Git, but for data.
Well friend, have you heard the good news? We’re building TerminusDB to provide distributed revision control for data. Databases in TerminusDB can be cloned, branched and merged with nary a migration script in sight.
With TerminusDB you can truly integrate data into your CI/CD pipelines.
You don’t need to fear your database anymore.
TerminusDB is free software, and is pretty new, and still under heavy development, but we’d love to have join us, the best place to get involved early is our Discord community.