
Part 2 of our Graph Fundamentals Series focuses on Labeled Property Graphs. The 4 part warts-and-all introduction to graph technologies covers RDF, Property Graphs, Graph Schemas, Linked Data, and concludes with an article called Why Graph Will Win. It should give you a solid introduction to the world of graph and associated challenges, while also offering a firm view that graph is the correct way to approach these complex problems. Enjoy!
Labeled Property Graphs vs RDF
The second major variant of graph databases is known as a property graph or labeled property graph (LPG). Property graphs are much simpler than RDF — they consist of a set of nodes and a set of edges, with each node and edge being essentially a ‘struct’ — a simple data structure consisting of keys and values (which in some cases may themselves be structs).
Nowadays JSON is the standard way of encoding these structs — each node and edge is a JSON document, with edges having special keys which indicate that the value represents a pointer to a node.
RDF uses URLs as identifiers for properties and entities, property graphs use simple strings — purely local identifiers. And while RDF uses the triple as the atom of data, property graphs do not — they are simply collections of arbitrary data-structures, some of which can point at other structures.
A third major difference is that RDF is intimately associated with the semantic web. There are many layers that have been built on top to provide descriptions of the semantics of the entities described in RDF graphs. Property graphs, on the other hand, do not attempt to be self-describing at all; the meaning and interpretation of the structures are left up to the consumer of the data. They are just keys and values and, with the exception of edge links and a few other special keys, you can interpret them however you want.
Pros & Cons of Labeled Property Graphs
CREATE (a { name: 'Andy', title: 'Developer' })
CREATE (b { name: 'Bob', title: 'Manager' })
MATCH (a),(b)
WHERE a.name = 'Andy' AND b.name = 'Bob'
CREATE (b)-[r:MANAGES]->(a)
This is an example of creating two nodes and an edge in Cipher, Neo4J’s self-rolled graph query and definition language. In the absence of universal identifiers, the nodes that were created have to be matched by a property value before the edge can be created.
To somebody coming from a semantic web background, property graphs seem like a very impoverished alternative.
I remember when I first came across Neo4j — the most popular property graph database on the market today — in the mid-2000s, being completely puzzled as to why anybody would want such a thing.
And indeed, this perspective remains common among RDF aficionados — almost all of whom were, until recently, ensconced in academia and trained in semantics and distinctly look down on the relatively primitive nature of labeled property graphs. This comes out most sharply in graph database conferences where one can almost taste the resentment that the property graph people feel towards the condescending RDF academic snobs who look down on them.
“It’s just a bunch of random structs pointing at one another — as if you took a program written in C and removed all the code leaving only the naked data structures and saved them to disk naked, without any meaningful typing or schema or any help in interpreting or constraining them.”
However, the property graph people persevered and while RDF and the semantic web might have the weight of academia and international standards bodies behind them, they have generally failed to make any significant impact upon the real world — while Neo4j and its host of modern imitators are by far the most popular type of graph database in the world and there are some very good reasons for this.
Firstly, the similarity to programming language data structures is no coincidence. Neo4j started out as a library for the Java programming language (hence the 4j) that enabled them to create and store graph-like data structures – this makes sense because Java as a language is particularly badly suited to modeling graph-like data structures.
By contrast, the semantic web community built the Jena framework in Java as it was meant to be — and ended up with a monstrosity of verbose class hierarchies.
Stripped-down data structures with pointers between them is a much, much better way of modeling graphs. Secondly, by ignoring all the fancy semantic stuff, the property graph people were not distracted by the outpouring of confusing, broken, and misconceived standards that the W3C and academic semantics community produced.
The property graph people, to their credit, took a pragmatic approach and focused on making a database that ordinary humans could understand. Furthermore, while the RDF community was always much more focused on semantics — with the graph structure being almost an implementation detail, a consequence of building everything on triples — property graphs were always fundamentally focused on the graph as the best abstraction for modeling the world. And as important use-cases emerged which used graph algorithms (fraud, page-rank, recommender systems) they were much better positioned to take advantage.
RDF has a pure graph structure at a low-level but is often a confusing mess at a high level, while property graphs are the opposite — nodes represent things that are close to things in the world, edges represent relationships between things — all very intuitive, who cares that at a low level it is a primitive mess?
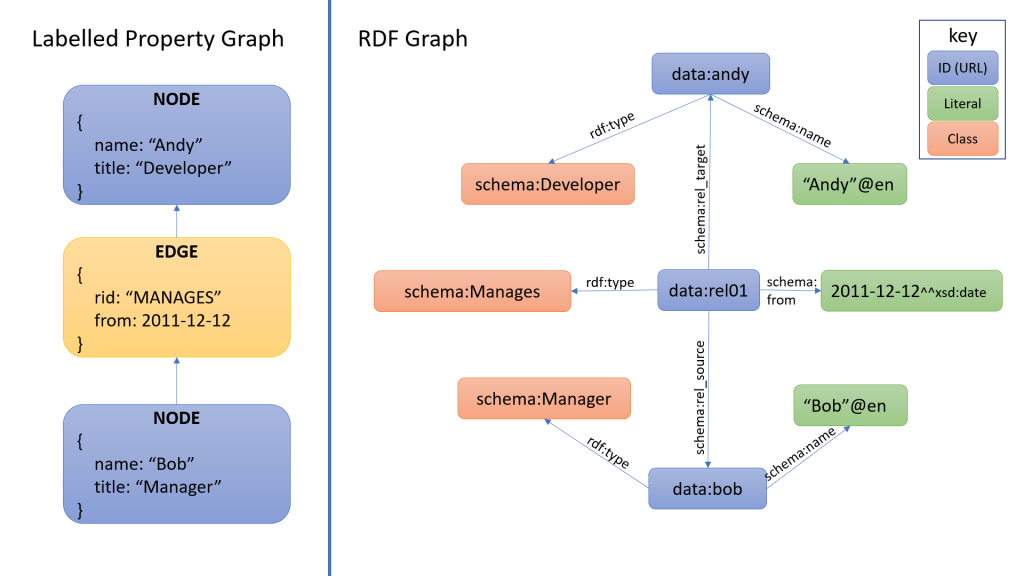
One consequence of this difference is that, when it comes to property graphs, it is relatively straightforward to add meta-data to edges — they are just structs after all and you can add whatever you like to the JSON blob representing an edge. This provides a straightforward way of adding qualifiers to edges — representing time, space, or any other qualifier you want — to represent relationships with weights and lifespans, for example.
In RDF, by contrast, edges of triples cannot have properties — it is relatively trivial to build more complex data structures in RDF which represent qualified edges — but there are umpteen different ways of doing so and coming up with a standard way of doing so is not of particular interest to the semantic web academic community, who are much more focused on expressiveness and inference than such solved trivia.
So, labeled property graphs provide a relatively simple mechanism that is easily understood by coders for modeling real-world things and qualified relationships between them as against a bewildering blizzard of complex concepts that any new entrant to RDF land must endure.
Over time, Neo4j developed, in an evolutionary way, a query language called Cypher that is reasonably intuitive for coders — including some cute ways of representing graph edges:
(a)-[relationship]->(b)
From the perspective of a formal query language, it is a mess — with structures that break compositionality for no good reason, and it remains a good 70 years behind the frontier of formal graph logic.
Nevertheless, what labeled property graphs provide remains better, in practice, than anything the semantic web community ever came up with. However, when dealing with very large graphs — billions of nodes and edges have become the norm today— their early pragmatism comes back to bite them with a vengeance.
When graphs get really big and complicated, without a formal mathematical-logical basis for reasoning about graph traversals, leaving it all up to the individual query writer falls to pieces — the heat death of the universe lies around every corner.
Furthermore, as graph databases move from being toys for enthusiastic coders into serious enterprise tools, constraints and schemata become very much more important — who the hell wants to maintain the structure of a billion node mission-critical enterprise knowledge graph without any support from the computer? And why would you do so — applying constraints and rules to data structures is exactly what computers are good at— with decades of formal logic research to draw on.
The cost of early pragmatism becomes a nightmare in the present because it is invariably impossible to engineer such fundamental aspects back into the core of the system.
Furthermore, as systems become ever bigger and more interconnected, jettisoning URLs in favor of local identifiers becomes an ever more serious impediment — throwing away universal, uniform, dereferenceable identifiers in the age of the web looks less and less wise.
The cost of stitching together systems of local identifies in every new case adds up to many many times more trouble than it would have taken to just adopt URLs as universal identifiers initially. Hence, despite their importance in the early days of graph databases, property graphs will likely fade out as knowledge graphs become adopted by enterprises and incorporated into their infrastructure — a well-defined schema is not optional in this — already they have been discarded by the best and most advanced new graph database providers.
This is the second part, focusing on Labeled Property Graphs, of a four-article series on graph fundamentals. The first article in the series covered RDF DB, the other major variant of graph databases around today, while the third and next part covers graph schema languages with a particular focus on OWL, the most ambitious attempt yet to provide us with a language for talking about data.