

Here at TerminusDB, we’ve been talking about database version control for a number of years. Others have joined us, Dolt and PlanetScale, are two such databases available on the market today.
However, we’ve made a mistake when talking about this. Yes, TerminusDB and TerminusX provide database version control, but it’s not really about version control data. These features are about collaboration and workflow.
There’s collaboration externally and collaboration internally and TerminusDB excels at both, but this article is focused on internal collaboration and using database version control tools to improve the way data, software, analysts, and domain professionals work together.
What does a database version control or database collaboration mean to the future of builders?
Version control, collaboration, they’re just words, aren’t they? They don’t really mean much when you use them in isolation, they represent things, maybe getting some help with your code, or rolling back to a previous version of it. Merely things, nothing to get you excited.
However, version control and collaboration are things to get excited about.
Let us look at how at the makeup of a data team, you have:
- Data engineers
- Software engineers
- Data scientists
- Knowledge engineers
- Analysts
- BI experts
- Project managers
- Business unit personnel
Then there are the software developers and domain experts, they need to be involved, after all, they’re the ones who are making requests and are closest to the data.
The data team may work as a central team, be part of a matrix structure servicing particular products or domains, or work in a decentralized domain-orientated organization. Whatever the setup, database version control will help improve collaboration, workflow, data accuracy, and development speed.
Within a data team, there is a crossover of knowledge and expertise. Software engineers will know about databases, data engineers will know about software and all the others will have varying degrees of technical knowledge. Getting these teams working closely together will result in many benefits, for example, cross-pollination of skills, improved data accuracy, and quicker time to market.
How TerminusDB’s database version control enables you to collaborate closely and build better
Before explaining how TerminusDB and TerminusX can harmonize your team to become more efficient at delivering products and services, let us first examine how our database version control works:
TerminusDB version control data technical overview
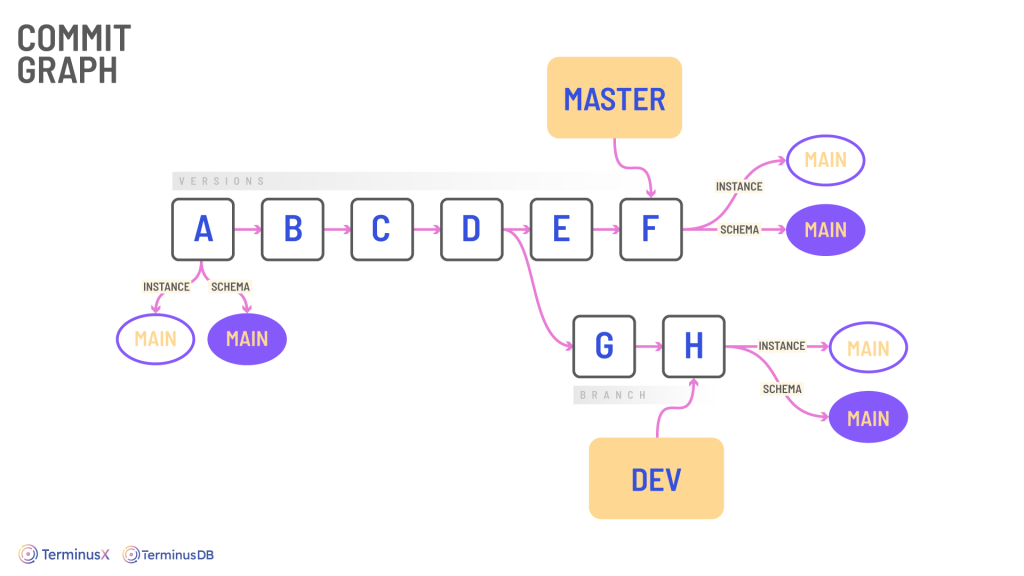
TerminusDB/X uses delta encoding: a way of storing and transmitting data in the form of deltas (differences) between sequential data rather than complete files. Deltas are stored in succinct terminusdb-store structures. Storing differences in this way is very efficient from a storage point of view, but it allows for an important part of version control: the ability to fork, branch, clone, and merge your data.
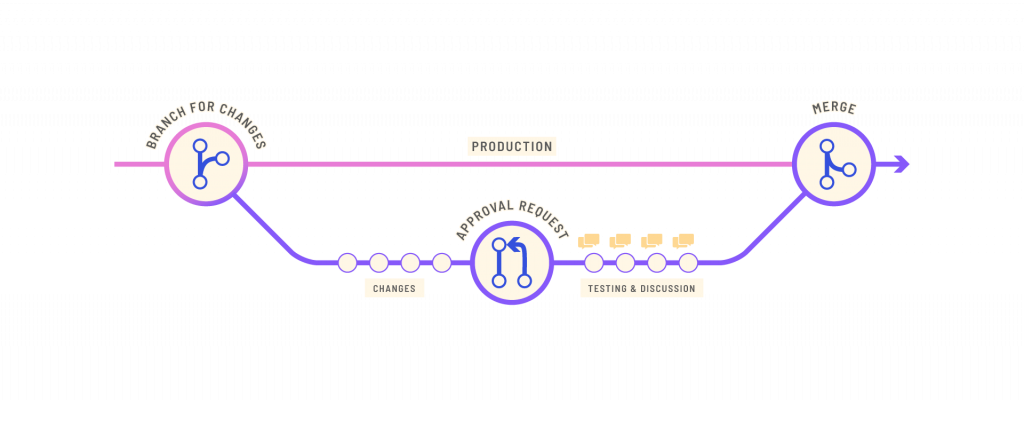
The database itself is immutable and this also provides beneficial features for version control and enables branch and merge, but it also stores all changes to data, and importantly schema, and records who changed what and when. Here you can add application auditing from the very start of your build, and have the ability to travel back in time to see (and revert to) any iteration of the past.
TerminusDB/X’s schema language enables documents and their relationships to be specified using simple JSON syntax. Schemas are flexible and extendible, with branch, merge, and time-travel all possible so you can get the semantics of your build right.
How all of this benefits you and your team
There’s a growing consensus that the way organizations work with data needs to be improved. There’s too much upkeep and time spent sourcing and cleaning data. A recent survey also highlighted that 97% of data engineers feel burned out and 70% are considering leaving their jobs within the next 12 months (check out our DataOps tools article for more info). This is not great reading and part of a bigger problem.
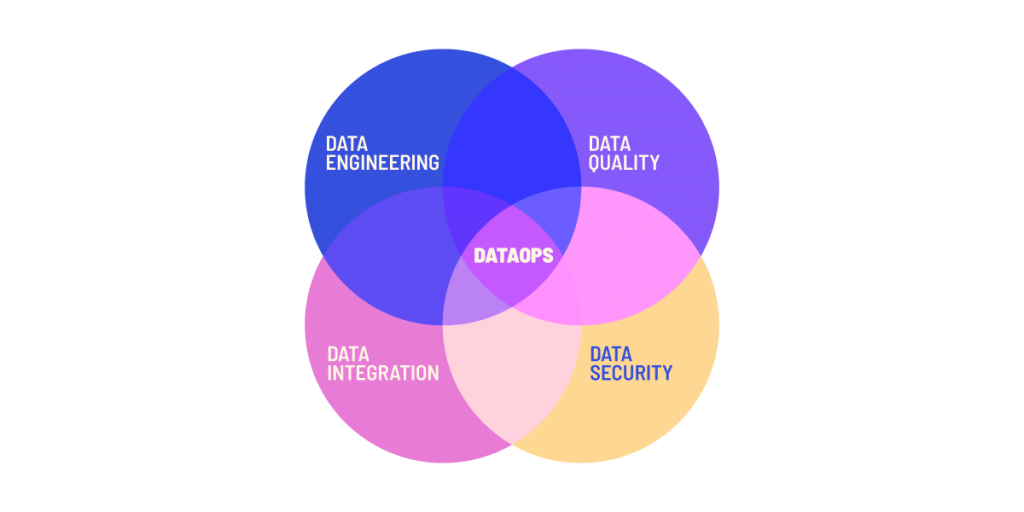
There are movements taking hold, such as DataOps, Data Mesh, and Data Fabric that are trying to address these problems, typically stemming from data warehouses and lakes. However, database version control can help alleviate problems with or without these movements.
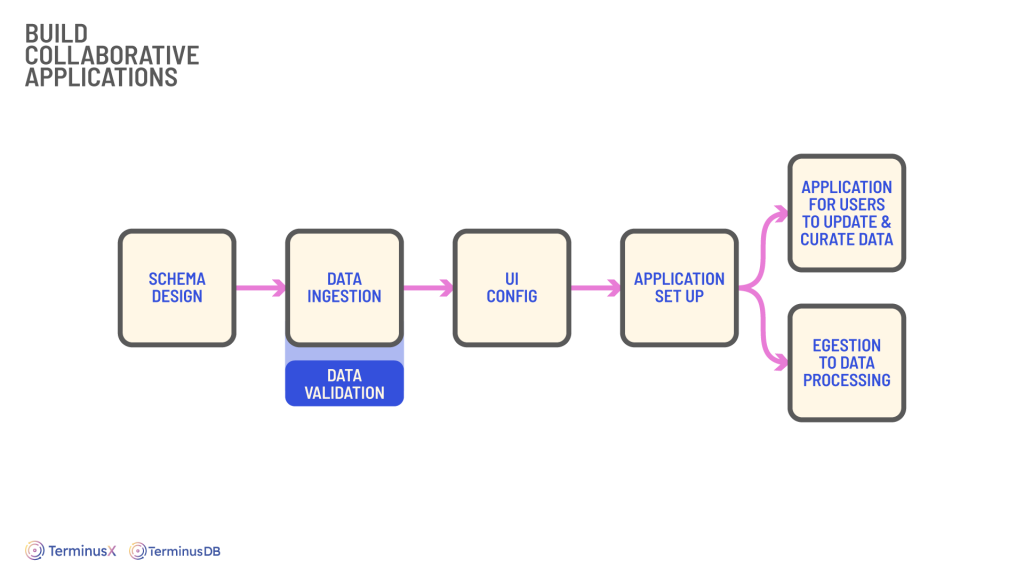
Firstly with the ability to branch data, it is quicker and easier to set up a development environment. Access is securely provided to whoever needs it and from here data, domain, analysts, and software professionals can work together to begin building features, apps, or gaining insights. This is all achieved without any disruption to the production database so business can keep ticking over while you and your team can work.
TerminusDB also facilitates workflows with approval processes. Changes by software developers can be checked over by data engineers, and vice versa. Importantly it is no longer siloed work, it’s regular discussions, conversations, and sharing of knowledge. Need to make sense of the data? Bring the domain experts in. Better communication generally means a better working relationship.
Developing and refining schema helps to improve development and because requirements change, so can the schema so development isn’t stuck to a rigid framework. Again, collaborating as a team, you can blueprint your build and iron out those bugs prior to launch. The schema aids data modeling, improves data quality, and for apps requiring UIs, is invaluable.
Finally, because TerminusDB is an immutable database, recording all changes, building auditing into your applications from inception automatically happens, with time travel, the ability to see differences in JSON documents, and roll back to previous versions, development time and accuracy is greatly improved.
So when we’ve talked about database version control in the past we made a mistake. It’s not about version control data, it’s about collaboration, workflow, and having the tools to work together as a team to get to market faster.
Our bad.