

Revolutionary approach to data management with Terminus DB’s latest release
October 2021, Dublin – TerminusDB today launched the next release of its version-controlled open-source database, uniquely combining the power of knowledge graphs with the simplicity of documents to give data engineers superpowers.
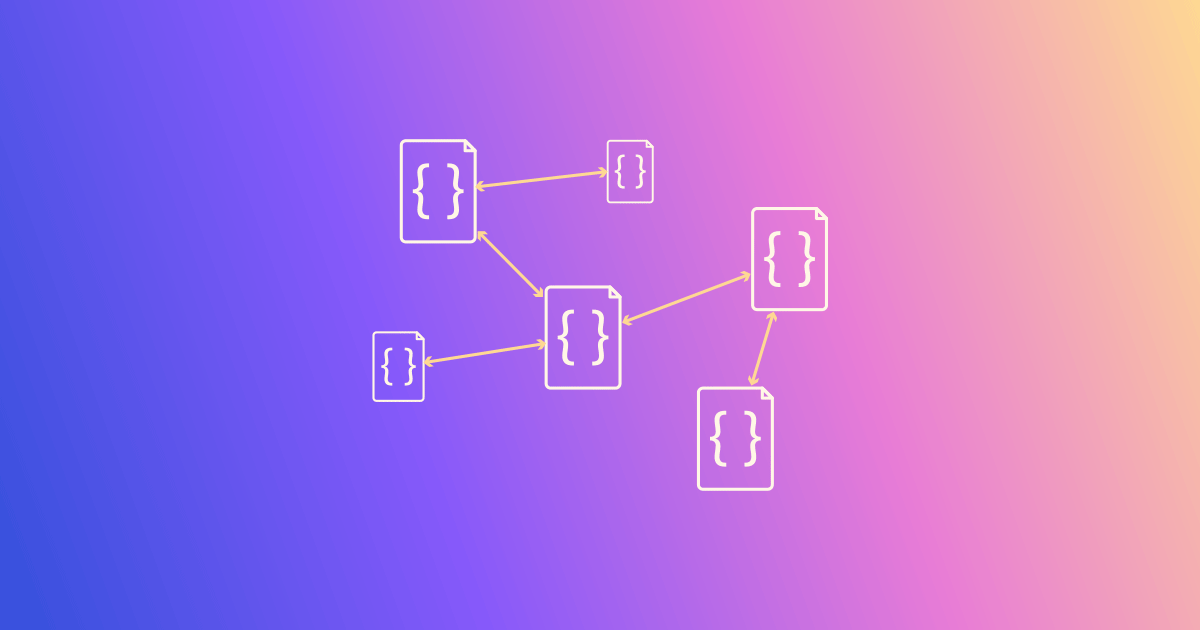
TerminusDB users can now create rich connected knowledge graphs taking in diverse datasets and use documents to organize data in meaningful ways. The result is a knowledge graph of JSON documents that can refer to each other to build a vibrant picture in data.
Gavin Mendel-Gleason, co-founder, said, “TerminusDB 10.0 is an exciting release, knowledge graphs have given unprecedented success to companies like Google and Facebook. We’ve made this latest release accessible to data developers who want to utilize siloed, structured, and unstructured data to build powerful applications and insights to drive business innovation.”
With an intuitive dashboard, Python, and Javascript client access, schema definition in JSON, and the ability to expose multiple operational APIs and analytical endpoints, TerminusDB 10.0 is the database to revolutionize data management.
Mendel-Gleason concluded, “We’ve built upon our version control for data that enables data teams to branch and merge their data assets to collaborate at the same time in a controlled way, and added the ability to link JSON documents in a powerful knowledge graph all through a radically simplified interface. We are excited to bring this revolutionary open-sourced data management tool to our growing community of users.”
Research communities, academics, and enterprise organizations continue to innovate their data in unique and insightful ways with TerminusDB and, thanks to early community betas, are already taking advantage of version 10.0.
For more information about TerminusDB 10.0 visit the documentation site.
Foundation
It all started on Terminus
The Galactic Empire is crumbling and darkness is on the horizon.
Sent to Terminus under a guise to use its superior database technology to record all human societies, the true meaning starts to become clear.
The Galactic Empire has lost its way and the days of centralization are coming to an end.
On Terminus a new way is being cultivated, a way that promotes freedom with control, a new empire. A better empire.
The Galactic Empire will not go without a final stand and war is coming.
The Foundation must rise.
TerminusDB 10.0 War Games is here.